스파크 완벽 가이드 - Chapter5. 구조적 API 기본 연산
by Gunju Ko
스파크 완벽 가이드 - 구조적 API 기본 연산
이 글은 “스파크 완벽 가이드” 책 내용을 정리한 글입니다.
저작권에 문제가 있는 경우 “gunjuko92@gmail.com”으로 연락주시면 감사하겠습니다.
구조적 API 기본 연산
- DataFrame은 ROW 타입이 레코드와 각 레코드에 수행할 연산 표현식을 나타내는 여러 컬럼으로 구성된다.
- 스키마는 각 컬럼명과 데이터 타입을 정의한다.
- DataFrame의 파티셔닝은 DataFrame이나 Dataset이 클러스터에서 물리적으로 배치되는 형태를 정의한다.
- 파티셔닝 스키마는 파티션을 배치하는 방법을 정의한다.
- 파티셔닝의 분할 기준은 특정 컬럼이나 비결정론적 값을 기반으로 설정할 수 있다.
// 스칼라 코드
val df = spark.read.format("json")
.load("/data/flight-data/json/2015-summary.json")
df.printSchema()
- DataFrame은 컬럼을 가지며 스키마로 컬럼을 정의한다.
스키마
- 스키마는 컬럼명과 데이터 타입을 정의한다.
- 데이터를 읽기 전에 스키마를 정의해야 하는지 여부는 상황에 따라 달라진다.
- 비정형 분석에서는 스키마 온 리드가 대부분 잘 동작한다. 단 정밀도는 떨어질 수 있다.
- 운영환경에서 ETL 작업을 수행한다면 직접 스키마를 정의하는게 좋다.
- CSV나 JSON 등의 데이터소스를 사용하는 경우 스키마 추론 과정에서 읽어 들인 샘플 데이터의 타입에 따라 스키마를 결정한다.
spark.read.format("json").load("/data/flight-data/json/2015-summary.json").schema
# 결과
StructType =
StructType(
StructField(DEST_COUNTRY_NAME, StringType, true),
StructField(ORIGIN_COUNTRY_NAME, StringType, true),
StructField(COUNT, LongType, true)
)
- 스키마는 여러 개의 StructField 타입 필드로 구성된 StructType 객체이다.
- StructField는 이름, 데이터 타입, 컬럼이 값이 없거나 널일 수 있는지 지정하는 불리언값을 가진다.
- 컬럼에 관련된 메타데이터를 지정할 수도 있다.
- 스키마는 복합 데이터 타입인 StructType을 가질 수 있다.
- 스파크는 런타임에 데이터 타입이 스키마의 데이터 타입과 일치하지 않으면 오류를 발생시킨다.
val myManualSchema = StructType(Array(
StructField("DEST_COUNTRY_NAME", StringType, true),
StructField("ORIGIN_COUNTRY_NAME", StringType, true),
StructField("count", LongType, false, Metadata.fromJson("..."))
))
val df = spark.read.format("json").schema(myManualSchema)
- 스키마는 자체 데이터 타입 정보를 사용한다.
컬럼과 표현식
- 컬럼은 표현식이다. (컬럼은 표현식의 일부 기능을 제공한다)
- 표현식으로 컬럼을 선택, 조작, 제거할 수 있다.
- 컬럼에 접근하려면 DataFrame이 필요하다.
- 컬럼의 내용을 수정하려면 DataFrame의 트랜스포메이션을 사용해야 한다.
컬럼
- col, column 함수 : 컬럼을 생성하거나 참조할 때 사용
col("someColumnName")
column("someColumnName")
// 스칼라에서는 $, '를 사용해서 컬럼을 참조할 수 있다.
$"myColumn"
'myColum
명시적 컬럼 참조
df.col("count")
- col 메서드를 사용해 명시적으로 컬럼을 정의하면 스파크는 분석기 실행 단계에서 컬럼 확인 절차를 생략한다.
표현식
- 표현식은 DataFrame 레코드의 여러 값에 대한 트랜스포메이션 집합을 의미한다. 여러 컬럼명을 입력으로 받아 식별하고, “단일 값”을 만들기 위해 다양한 표현식을 각 레코드에 적용하는 함수라고 생각할 수 있다.
- 표현식은 expr 함수로 사용할 수 있다.
// 아래 구문은 동일하다.
expr("someCol")
col("someCol")
- 컬럼은 단지 표현식일 뿐이다.
- 컬럼과 컬럼의 트랜스포메이션은 파싱된 표현식과 동일한 논리적 실행 계획으로 컴파일된다.
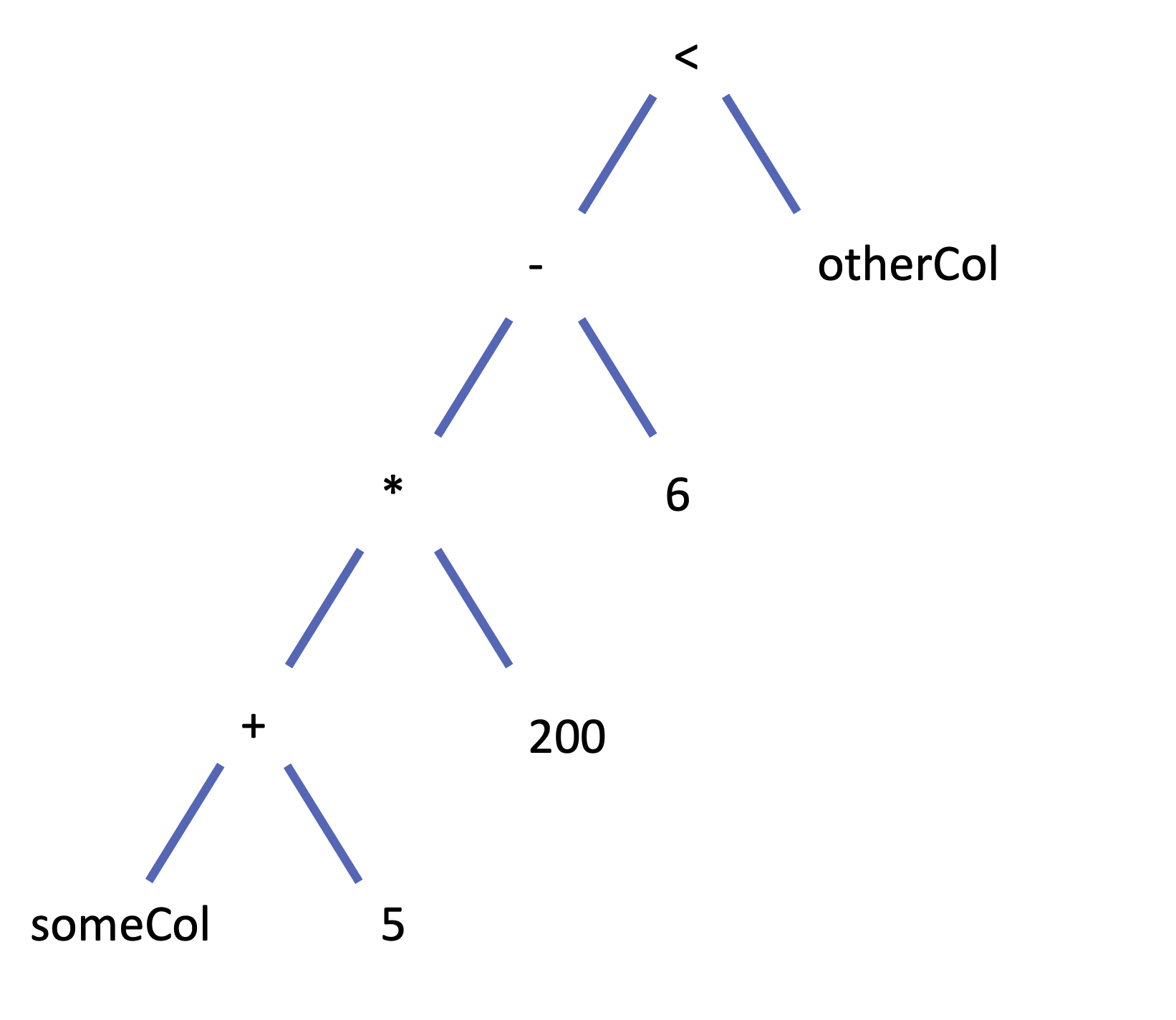
// 아래 코드는 동일한 논리적 실행 계획으로 컴파일 된다.
(((col("someCol") + 5) * 200) - 6) < col("otherCol")
expr("(((someCol + 5) * 200) - 6) < otherCol")
참고) 논리적 트리
// 데이터프레임 컬럼에 접근하기
spark.read.format("/json").load("/data/flight-data/json/2015-summary.json").columns
레코드와 로우
- DataFrame에서 각 로우는 하나의 레코드이다.
- 레코드를 Row 객체로 표현한다.
- Row 객체는 내부에 바이트배열일 가진다.
- 이 바이트 배열 인터페이스는 오직 컬럼 표현식으로만 다룰 수 있다.
- DataFrame을 사용해 드라이버에 개별 로우를 반환하는 명령은 항상 하나 이상의 Row 타입을 반환한다.
로우 생성하기
- Row 객체는 스키마정보를 가지고 있지 않는다. (DataFrame만 유일하게 스키마를 갖는다.)
- Row 객체를 직접 생성하려면 DataFrame의 스키마와 같은 순서로 값을 명시해야 한다.
val myRow = Row("Hello", null, 1, false)
myRow(0)
myRow.getString(0)
myRow.getInt(2)
DataFrame의 트랜스포메이션
- DataFrame을 다루는 방법은 몇가지 주요 작업으로 나눌 수 있다.
- 로우나 컬럼 추가
- 로우나 컬럼 제거
- 로우를 컬럼으로 변환하거나, 그 반대로 변환
- 컬럼값을 기준으로 로우 순서 변경
데이터프레임 생성하기
val df = spark.read.format("json").load("/data/flight-data/json/2015-summary.json")
df.createOrReplaceTempView("dfTable")
val myManualSchema = new StructType(Array(
new StructField("some", StringType, true),
new StructField("col", StringType, true),
new StructField("names", LongType, false)
))
val myRows = Seq(Row("Hello", null, 1L))
val myRDD = spark.sparkContext.parallelize(myRows)
val myDf = spark.createDataFrame(myRDD, myManualSchema)
_implicit는 기본 스칼라 객체를 DataFrame으로 변환하는데 사용된다. _implicit를 임포트해서 Seq 데이터 타입에 toDf 함수를 활용하여 DataFrame으로 변환할 수 있다.
select와 selectExpr
- 데이터 테이블에 SQL을 실행하는 것처럼 데이터프레임에서도 SQL을 사용할 수 있다.
// 스칼라 코드
df.select("DEST_COUNTRY_NAME").show(2)
df.select("DEST_COUNTRY_NAME", "ORIGIN_COUNTRY_NAME").show(2)
df.select(
df.col("DEST_COUNTRY_NAME"),
col("DEST_COUNTRY_NAME"),
column("DEST_COUNTRY_NAME"),
'DEST_COUNTRY_NAME,
$"DEST_COUNTRY_NAME",
expr("DEST_COUNTRY_NAME")
).show(2)
df.select(expr("DEST_COUNTRY_NAME AS destination")).show(2)
df.select(expr("DEST_COUNTRY_NAME AS destination")).alias("DEST_COUNTRY_NAME").show(2)
df.selectExpr("DEST_COUNTRY_NAME AS destination").show(2)
- selectExpr 메서드는 새로운 DataFrame을 생성하는 복잡한 표현식을 간단하게 만드는 도구이다.
df.selectExpr("*", "(DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as withinCountry")
.show(2)
- select 표현식에는 DataFrame의 컬럼에 대한 집계 함수를 지정할 수 있다.
df.selectExpr("avg(count)", "count(distinct(DEST_COUNTRY_NAME))").show(2)
컬럼 추가하기
- withColmn 메서드를 사용해서 컬럼을 추가할 수 있다.
- withColumn 메서드는 2개의 인수를 사용한다. 하나는 컬럼명이고 다른 하나는 값을 생성하는 표현식이다.
df.withColumn("numberOne", lit(1))
df.withColumn("withinCountry", expr("ORIGIN_COUNTRY_NAME == DEST_COUNTRY_NAME"))
// 컬럼명 변경
df.withColumn("Destination", expr("DEST_COUNTRY_NAME")).columns
df.withColumnRenamed("DEST_COUNTRY_NAME", "dest")
예약 문자와 키워드
- 공백이다 하이픈(-) 같은 예약 문자는 컬럼명에 사용할 수 없다. 사용하려면 백틱(`)문자를 이용해 이스케이핑해야 한다.
대소문자 구분
- 기본적으로 대소문자를 가리지 않는다.
set spark.sql.caseSensitive true
- 위 설정을 사용해 대소문자를 구분하게 만들 수 있다.
컬럼 제거하기
df.drop("ORIGIN_COUNTRY_NAME")
데이터 타입 변경하기
df.withColumn("count", col("count").cast("string"))
로우 필터링하기
- DataFrame의 가장 일반적인 필터링 방법은 문자열 표현식이나 컬럼을 다루는 기능을 이용해 표현식을 만드는 거다.
- DataFrame의 where 메서드나 filter 메서드로 필터링할 수 있다.
- 두 메서드 모두 같은 연산을 수행하며 같은 파라미터 타입을 사용한다.
df.filter(col("count") < 2)
df.where("count < 2")
- 같은 표현식에 여러 필터를 적용해야 할 때도 있다. 하지만 스파크는 자동으로 필터의 순서와 상관없이 동시에 모든 필터링 작업을 수행하기 때문에 항상 유용한 것은 아니다. 그러므로 여러 개의 AND 필터를 지정하려면 차례대로 필터를 연결하고 판단은 스파크에 맡겨야한다.
df.where(col("count") < 2).where(col("ORIGIN_COUNTRY_NAME") =!= "Croatia")
- 스칼라에서는 반드시
=!====연사자를 사용해야 한다. (사실 스파크의 Column 클래스에 정의된 함수이다.)- 컬럼 표현식과 문자열을 비교할 때
=!=연산자를 사용하면, 컬럼의 실제값을 비교 대상 문자열과 비교한다.
- 컬럼 표현식과 문자열을 비교할 때
고유한 로우 얻기
- DataFrame의 모든 로우에서 중복 데이터를 제거할 수 있는 distinct 메서드를 사용해 고윳값을 찾을 수 있다.
df.select("ORIGIN_COUNTRY_NAME", "DEST_COUNTRY_NAME").distinct().count()
무작위 샘플 만들기
- 무작위 샘플 데이터를 얻으려면 sample 메서드를 사용한다.
임의 분할하기
val dataFrames = df.randomSplit(Array(0.25, 0.75), seed)
로우 합치기와 추가하기
- DataFrame은 불변성을 가지므로 레코드 추가는 불가능하다.
- DataFrame에 레코드를 추가하려면 원본 DataFrame을 새로운 DataFrame과 통합해야 한다.
- 통합하려는 두 개의 DataFrame은 반드시 동일한 스키마와 컬럼 수를 가져야한다.
- union 메서드는 현재 스키마가 아닌 컬럼 위치를 기반으로 동작한다. 따라서 사용자가 생각한 대로 자동 정렬되지 않을 수 있다.
df.union(newDf)
로우 정렬하기
- sortBy 또는 orderBy 사용
- 기본 동작은 오름차순 정렬이다.
- 정렬 기준을 명확히 하려면 asc나 desc 함수를 사용한다.
df.sort("count")
df.orderBy("count", "DEST_COUNTRY_NAME")
df.orderBy(desc("count"), asc("DEST_COUNTRY_NAME"))
- asc_nulls_first, desc_nulls_first, asc_nulls_last, desc_nulls_last 메서드를 사용하여 정렬된 DataFrame에서 널 값이 표시되는 기준을 지정할 수 있다.
- 트랜스포메이션을 처리하기 전에 성능을 최적화하기 위해 파티션별 정렬을 수행하기도 한다. 파티션별 정렬은 sortWithinPartitions 메서드로 할 수 있다.
spark.read.format("json").load("/data/flight-data/json/*-summary.json")
.sortWithPartition("count")
로우 수 제한하기
- limit 메서드 사용
df.limit(5)
repartition과 coalesce
- 최적화 기법으로 자주 필터링하는 컬럼을 기준으로 데이터를 분할할 수 있다. 이를 통해 파티셔닝 스키마와 파티션 수를 포함해 클러스터 전반의 물리적 데이터 구성을 제어할 수 있다.
- repartition 메서드를 호출하면 무조건 전체 데이터를 셔플한다. 향후에 사용할 파티션 수가 현재 파티션수보다 많거나 컬럼을 기준으로 파티션을 만드는 경우메나 사용해야 한다.
df.rdd.getNumPartitions
df.repartition(5)
df.repartition(col("DEST_COUNTRY_NAME"))
df.repartition(5, col("DEST_COUNTRY_NAME"))
-
특정 컬럼을 기준으로 자주 필터링한다면 자주 필터링하는 컬럼을 기준으로 파티션을 재분배하는것이 좋다.
-
coalesce는 전체 데이터를 셔플하지 않고 파티션을 병합하려는 경우에 사용한다.
- 파티션수를 줄이려면 repartition 대신에 coalesce를 사용해야 한다.
df.repartition(5, col("DEST_COUNTRY_NAME")).coalesce(2)
드라이버로 로우 데이터 수집하기
- 로컬에서 데이터를 다루려면 드라이버로 데이터를 수집해야 한다.
- collect 메서드는 전체 DataFrame의 모든 데이터를 수집하며, take 메서드는 상위 N개의 로우를 반환한다.
- toLocalIterator 메서드는 반복자로 모든 파티션의 데이터를 드라이버에 전달한다.
val collectDF = df.limit(10)
collectDF.take(5)
collectDF.show()
collectDF.toLocalIterator()
드라이버로 모든 컬렉션을 수집하는 작업은 매우 큰 비용이 발생한다.