Stream DSL
by Gunju Ko
Streams DSL
이 글은 Streams DSL를 번역한 글이다. 잘못된 번역이 있을 수 있으며 생략된 부분이 있기 때문에 더 자세한 내용은 원글을 참고하길 바란다.
Kafka Stream DSL (Domain Specific Language)는 Stream Processor API를 사용해서 구현되어 있다. 초보자들은 DSL를 사용하는게 좋다. 대부분의 데이터 처리 작업은 DSL를 사용해서 단 몇 줄로 처리할 수 있다.
Overview
Processor API와 비교했을때 DSL만 지원되는 개념
- Kafka Stream DSL은 스트림과 테이블에 대한 추상화(KStream, KTable, GlobalKTable)를 제공한다. 스트림과 테이블을 일급 클래스로 제공하는것은 중요하다. 왜냐하면, 대부분의 경우에 스트림과 테이블을 조합해서 사용하기 때문이다.
- Kafka Stream DSL은 선언적인 함수형 스타일의 stateless transformantion을 제공한다(map, filter 등). 뿐만 아니라 stateful transformation을 제공한다. (aggregation, join, windowing)
DSL를 사용해서 Topology를 구성할 수 있다. Topology를 구성하는 순서는 아래와 같다.
- 카프카 토픽으로부터 데이터를 읽어드리는 Input 스트림을 하나이상 지정해라
- Input 스트림의 Transformation를 구성해라
- ouput 스트림을 카프카 토픽에 써라. 혹은 Interactive quries를 사용해서 어플리케이션의 처리 결과를 REST API등을 통해서 노출시켜라
어플리케이션이 실행되면, 정의된 Topology 프로세서들이 계속해서 실행된다. Kafka Streams Javadocs에서도 관련된 내용을 볼 수 있다.
Creating Source Streams from Kafka
카프카 토픽으로부터 데이터를 읽어들이는 것인 굉장히 쉽다.
input topic -> KStream
특정 카프카 토픽으로부터 KStream을 생성할 수 있다. KStream은 분할된 레코드 스트림을 나타낸다. 스트림 어플리케이션이 여러 서버에서 실행된다면, 각각의 어플리케이션이 생성하는 KStream 객체는 input 토픽의 일부 파티션 데이터로 채워진다. 하지만 모든 KStream 객체를 하나의 집합으로 본다면, input 토픽의 모든 파티션 데이터는 처리된다. KStream에 관한 더 자세한 내용은 링크를 참고해라
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Long> wordCounts = builder.stream(
"word-counts-input-topic", /* input topic */
Consumed.with(
Serdes.String(), /* key serde */
Serdes.Long() /* value serde */
);
Serdes를 명시적으로 지정하지 않으면, 디폴트 Serdes 클래스가 사용되며 디퐅트 Serdes 클래스는 설정을 통해 지정할 수 있다. Input 토픽 record의 key 혹은 value 타입이 디폴트 Serdes 클래스와 일치하지 않는다면 명시적으로 Serdes 클래스를 지정해야한다. 더 자세한 내용은 Data Types and Serialization를 참고해라.
input topic -> KTable
특정 카프카 토픽으로부터 KTable를 생성할 수 있다. 이 경우 토픽은 Chanelog Stream으로 해석된다. 동일한 키를 가지는 Record는 해당 레코드에 대해 INSERT/UPDATE(value가 널이 아닌 경우) 혹은 DELETE(value가 널인 경우)로 해석된다.
테이블의 이름을 반드시 지정해주어야 한다.(정확하게는 테이블을 백업하는 내부 State Store의 이름을 지정해야 한다.) 이는 테이블에 Interactive queries를 지원하는데 필요하다. 이름을 지정해주지 않으면 쿼리할 수 없으며 State Store의 이름은 내부적으로 지정된다. KStream과 마찬가지로 Input 토픽 record의 key 혹은 value 타입이 디폴트 Serdes 클래스와 일치하지 않는다면 명시적으로 Serdes 클래스를 지정해야한다.
Input 토픽으로부터 데이터를 읽어드릴때 auto.offset.reset에 속성에 따라 데이터를 읽어오는 위치를 정한다. 따라서 auto.offset.reset의 값에 따라서 table이 달라질 수 있다.
input topic -> GlobalKTable
지정된 카프카 토픽을 GlobalKTable로 읽는다. 토픽은 changelog stream으로 해석되며, record의 value가 널이 아닌 경우에는 동일한 키를 가진 record에 대한 UPSERT로 해석된다. record가 널인 경우에는 해당 키에 대한 DELETE로 해석된다. GlobalKTable의 경우, 로컬 GlobalKTable 객체는 모든 Input 토픽 파티션의 데이터로 채워진다. 결과적으로 모든 어플리케이션은 모든 Input 토픽의 파티션 데이터를 읽어온다. 테이블에 대한 이름을 지정해야 한다. (더 정확히는 State Store의 이름) 이름은 테이블에 대한 Interactive queries를 지원하는데 필요하다. 만약에 이름을 지정하지 않으면 테이블을 쿼리 할 수 없으며 StateStore의 이름은 내부적으로 지정된다.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.GlobalKTable;
StreamsBuilder builder = new StreamsBuilder();
GlobalKTable<String, Long> wordCounts = builder.globalTable(
"word-counts-input-topic",
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(
"word-counts-global-store" /* table/store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Long()) /* value serde */
);
Input 토픽 record의 키와 value 타입이 설정된 default SerDes와 일치하지 않는 경우에는, SerDes를 명시적으로 지정해야 한다. 더 자세한 내용은 Data Types and Serialization를 참고해라
참고 StreamBuilder.table 혹은 StreamBuilder.globalTable 메소드를 통해서 바로 KTable 혹은 GlobalKTable을 생성하는 경우에는 State Store의 백업을 위한 changelog 토픽이 생성되지 않는다.
Transformation a Stream
KStream과 KTable은 다양한 Transformation Operation을 지원한다. 각 Operation들은 하나 이상의 연결된 Processor로 변형되어 Topology를 구성하게 된다. KStream과 KTable의 모든 Transformation 함수는 제네릭으로 정의되어 있다. 따라서 사용자가 input과 output의 타입을 결정할 수 있다. KStream의 Transformation 중 일부는 하나 이상의 KStream을 생성한다. 예를 들어 filter나 map은 새로운 KStream을 하나 생성하지만, branch는 여러개의 KStream을 생성할 수 있다. 또한 KStream으로 KTable을 생성할 수 있다. 예를 들어 KStream의 aggregation을 하면 KTable이 생성된다. 모든 KTable Transformation은 오로지 KTable만 생성할 수 있다. 그러나 Kafka Streams DSL은 KTable을 KStream으로 변형하는 특별한 함수를 제공한다. 이러한 Transformation 메소드들은 체이닝 될 수 있으며 복잡한 Topology를 구성할 수 있다.
Stateless transformations
Stateless transformations는 처리를 위해 상태를 저장할 필요가 없다. 따라서 연관된 Processor가 State Store를 필요로하지 않는다. Kafka 0.11.0 버전 이상부터는 Stateless KTable Transformation 결과를 구체화할 수 있다. 이는 interactive queries를 통해서 결과를 쿼리할 수 있도록 해준다. KTable을 구체화하기 위해서는 stateless 연산에 선택적 파라미터인 queryableStoreName를 넘겨주어야 한다.
아래의 메소드에 대한 더 자세한 내용은 KStream, KTable를 참고하길 바란다.
Branch
- KStream -> KStream[]
KStream을 주어진 조건에 따라서 하나 이상의 KStream으로 쪼갠다. 조건들은 순서대로 적용되며 처음으로 만족하는 조건에 따라서 Output Stream이 결정된다. 만약에 n번째 조건이 처음으로 만족된다면 n번째 Output Stream으로 레코드가 전달된다. 만약에 만족하는 조건이 없는경우 Record는 버려진다. 만약에 조건에 따라서 다른 토픽으로 Record를 전달하고자 할 때 유용하다
Stream<String, Long> stream = ...;
KStream<String, Long>[] branches = stream.branch(
(key, value) -> key.startsWith("A"), /* first predicate */
(key, value) -> key.startsWith("B"), /* second predicate */
(key, value) -> true /* third predicate */
);
// KStream branches[0] contains all records whose keys start with "A"
// KStream branches[1] contains all records whose keys start with "B"
// KStream branches[2] contains all other records
Filter
- KStream -> KStream
- KTable -> KTable
각 Record들이 특정 조건이 만족하는지를 보고, 특정 조건이 만족하는 경우에만 Output Stream으로 전달한다.
KStream<String, Long> stream = ...;
// A filter that selects (keeps) only positive numbers
// Java 8+ example, using lambda expressions
KStream<String, Long> onlyPositives = stream.filter((key, value) -> value > 0);
FilterNot
Filter와 반대로 동작한다.
FlatMap
- KStream -> KStream
하나의 Record로 0개 이상의 Record을 생성할 때 사용한다. Record의 Key와 Value값을 바꿀 수 있으며 타입 또한 바꿀 수 있다. Stream이 re-partition되어야 한다고 표시한다 : flatMap 이후에 grouping 혹은 join을 할 경우에 Records의 re-partitioning이 일어날 수 있다. 가능하면 flatMapValues를 사용해라 (이 경우 re-partitioning이 일어나지 않는다)
KStream<Long, String> stream = ...;
KStream<String, Integer> transformed = stream.flatMap(
// Here, we generate two output records for each input record.
// We also change the key and value types.
// Example: (345L, "Hello") -> ("HELLO", 1000), ("hello", 9000)
(key, value) -> {
List<KeyValue<String, Integer>> result = new LinkedList<>();
result.add(KeyValue.pair(value.toUpperCase(), 1000));
result.add(KeyValue.pair(value.toLowerCase(), 9000));
return result;
}
);
Foreach
- KStream -> void
- KTable -> void
Terminal operation : 각 Record에 대해서 Stateless한 작업을 수행한다. 그리고 Record에 대한 처리작업을 종료한다. 만약에 foreach 문안에서 외부 시스템 연동 등의 작업을 한다면 이는 부작용을 일으킬 수 있다. 외부 시스템은 카프카가 추적할 수 없기 때문에 카프카가 제공하는 processing.guarantee가 예상대로 동작하지 않을 수 있다.
GroupByKey
- KStream -> KGroupedStream
키를 이용해서 Record들을 그룹화한다. 그룹화는 Stream 혹은 Table를 aggregating하기 위한 전제 조건이다. 또한 후속 Operation들을 위해서 Record들이 Key로 적절히 분할되도록 한다. 만약에 GroupByKey의 결과인 KGroupedStream의 Key, Value 타입이 디폴트 Serdes와 일치하지 않는 경우에는 명시적으로 Serdes를 지정해주어야 한다.
Note
- Grouping vs. Windowing : 관련된 연산은 Windowing이다. Windowing을 통해서 동일한 키를 가진 Record 그룹을 window라고 불리는 하위 그룹으로 나누는 작업을 제어할 수 있다. 이를 통해서 windowed aggregations 혹은 windowed joined과 같은 stateful 연산을 할 수 있다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다 : groupByKey는 groupBy보다 바람직하다. 왜냐하면 Stream이 re-partitioning 되어야 하는 경우에만 re-partition 하기 때문이다. 하지만 groupByKey는 key나 key의 타입을 수정하지 못한다.
KStream<byte[], String> stream = ...;
// Group by the existing key, using the application's configured
// default serdes for keys and values.
KGroupedStream<byte[], String> groupedStream = stream.groupByKey();
// When the key and/or value types do not match the configured
// default serdes, we must explicitly specify serdes.
KGroupedStream<byte[], String> groupedStream = stream.groupByKey(
Serialized.with(
Serdes.ByteArray(), /* key */
Serdes.String()) /* value */
);
GroupBy
- KStream -> KGroupedStream
- KTable -> KGroupedTable
새로운 Key로 그룹화한다. 테이블을 그룹화할 때 새로운 value와 value 타입을 지정할 수 도있다. groupBy는 selectKey.grouByKey와 같다. 그룹화는 Stream 혹은 Table를 aggregating하기 위한 전제 조건이다. 후속 Operation들을 위해서 Record들이 Key로 적절히 분할되도록 한다. 만약에 GroupBy의 결과인 KGroupedStream 혹은 KGroupedTable의 Key, Value 타입이 디폴트 Serdes와 일치하지 않는 경우에는 명시적으로 Serdes를 지정해주어야 한다.
항상 re partitioning 된다. 따라서 가능하면 GroupByKey를 사용해라
KStream<byte[], String> stream = ...;
KTable<byte[], String> table = ...;
// Java 8+ examples, using lambda expressions
// Group the stream by a new key and key type
KGroupedStream<String, String> groupedStream = stream.groupBy(
(key, value) -> value,
Serialized.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.String()) /* value */
);
// Group the table by a new key and key type, and also modify the value and value type.
KGroupedTable<String, Integer> groupedTable = table.groupBy(
(key, value) -> KeyValue.pair(value, value.length()),
Serialized.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.Integer()) /* value (note: type was modified) */
);
Map
- KStream -> KStream
하나의 Record를 다른 Record를 만든다. Key와 Value 값을 수정할 수 있으며 타입도 바꿀 수 있다. Map 연산 이후에 Aggregating을 하거나 Join을 한다면 re-partitioning 될 수 있다. 가능하면 mapValues를 사용해라. mapValues는 re-partitioning을 유발하지 않는다.
KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
// Note how we change the key and the key type (similar to `selectKey`)
// as well as the value and the value type.
KStream<String, Integer> transformed = stream.map(
(key, value) -> KeyValue.pair(value.toLowerCase(), value.length()));
MapValues
- KStream -> KStream
- KTable -> KTable
하나의 Record를 다른 Record로 만든다. 이 때 Key는 변하지 않고 Value만 변한다. map과 다르게 re-partitioning을 유발하지 않기 때문에 가능하면 mapValues를 사용해라
KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
KStream<byte[], String> uppercased = stream.mapValues(value -> value.toUpperCase());
Peek
- KStream -> KStream
각 Record에 대해서 Stateless한 연산을 수행한다. 그리고 변경되지 않은 스트림을 반환한다. peek는 Input 스트림을 그래도 반환한다. Input 스트림을 수정해야 하는 경우에는 map 또는 mapValues를 사용해라 foreach와 달리 각 Record에 대해서 처리를 한 뒤에도 처리가 계속된다. (foreach는 터미널 연산이다)
peek는 로깅 또는 디버깅등을 할 때 유용하다.
Processing guarantees에 대한 참고 사항 : 만약에 peek 함수안에서 외부 시스템과 연동을 한다면, 이는 processing.guarantees의 혜택을 받지 못하게 된다.
KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
KStream<byte[], String> unmodifiedStream = stream.peek(
(key, value) -> System.out.println("key=" + key + ", value=" + value));
- KStream → void
터미널 연산 : record를 System.out를 통해서 프린트한다. print()를 호출하는 것은 다음과 같은 작업을 하는 것과 같다.
foreach((key, value) -> System.out.println(key + ", " + value))
아래는 간단한 예제이다.
KStream<byte[], String> stream = ...;
// print to sysout
stream.print();
// print to file with a custom label
stream.print(Printed.toFile("streams.out").withLabel("streams"));
SelectKey
- KStream -> KStream
각 레코드의 키를 새롭게 할당한다. (키의 타입이 바뀔 수도 있다) select(mapper)를 호출하는 것은 아래와 같다.
map((key, value) -> mapper(key, value), value)
스트림에 re-partitioning 되어야 한다고 표시한다 : selectKey 이후에 join 혹은 grouping을 하는 경우에는 레코드의 re-partitioning 이 일어난다.
KStream<byte[], String> stream = ...;
// Derive a new record key from the record's value. Note how the key type changes, too.
// Java 8+ example, using lambda expressions
KStream<String, String> rekeyed = stream.selectKey((key, value) -> value.split(" ")[0])
Table to Stream
- KTable -> KStream
Table의 change log 스트림을 가져온다.
KTable<byte[], String> table = ...;
// Also, a variant of `toStream` exists that allows you
// to select a new key for the resulting stream.
KStream<byte[], String> stream = table.toStream();
Stateful transformations
Stateful transformations는 input Record를 처리하기 위해서 상태에 의존한다. 또한 스트림 프로세서와 연관된 State Store를 필요로 한다. 예를 들어, aggregating operations에서 가장 최신의 결과를 가져오기 위해서 state store가 사용된다. State Store는 fault-tolerant 하다. 장애 발생 후 Kafka Stream은 처리작업을 다시 시작하기 전에 State Store를 완전히 복구한다. DSL의 Stateful transformations는 다음과 같다.
- Aggregating
- Joining
- Windowing
- Applying custom processors and transformers,
아래 그림은 각 연산들의 관계를 보여준다.
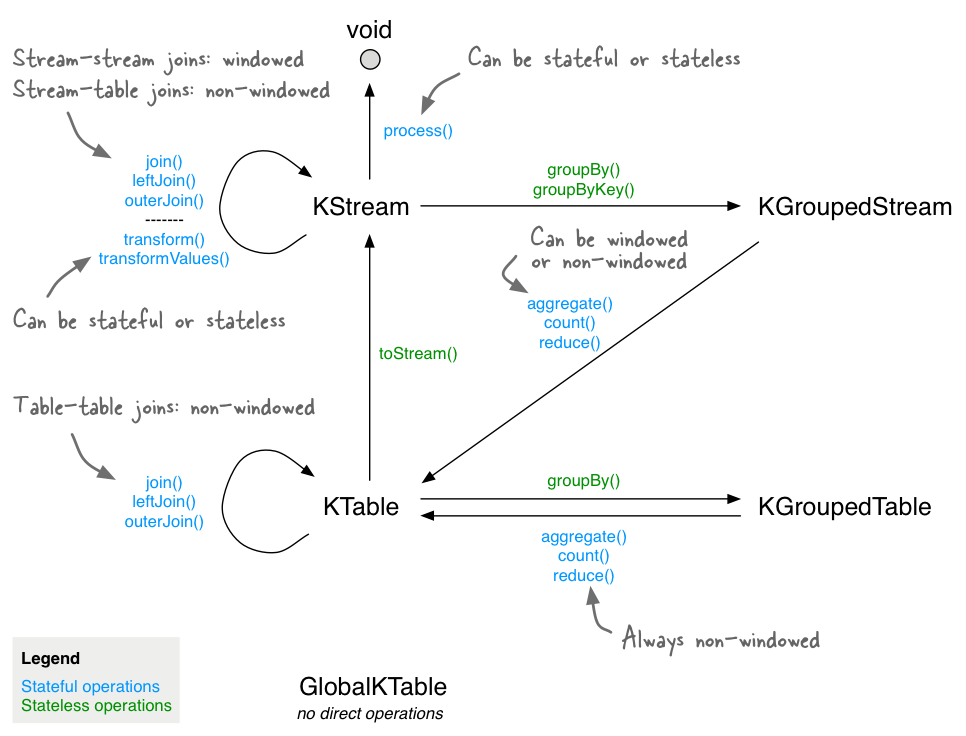
Aggregating
Record들이 groupBy 혹은 groupByKey로 그룹화되면, KGroupedStream 혹은 KGroupedTable로 표현된다. 그리고 KGroupedStream, KGroupedTable은 reduce 같은 연산을 통해서 집계 될 수 있다. Aggregations는 키를 기반으로 한 연산이기 때문에 항상 동일한 키를 가지는 Record들을 집계한다.
Aggregate (non windowed)
- KGroupedStream -> KTable
- KGroupedTable -> KTable
Record들을 키를 이용해서 Record들의 value를 집계한다. Aggregating은 reduce의 일반화이며, 집계된 value가 input value와 다른 타입을 가질 수도 있다. 그룹화된 Stream을 집계할 때, initializer와 adder를 제공해야 한다. initializer를 통해서 초기값을 전달할 수 있으며, adder를 이용해서 이전값과 새로운 값을 어떻게 집계할 것인지를 제공한다. 그룹화된 테이블을 집계할 경우에는 subtractor를 추가적으로 제공해야 한다.
KGroupedStream<byte[], String> groupedStream = ...;
KGroupedTable<byte[], String> groupedTable = ...;
// Java 8+ examples, using lambda expressions
// Aggregating a KGroupedStream (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedStream = groupedStream.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
Materialized.as("aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long()); /* serde for aggregate value */
// Aggregating a KGroupedTable (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
(aggKey, oldValue, aggValue) -> aggValue - oldValue.length(), /* subtractor */
Materialized.as("aggregated-table-store") /* state store name */
.withValueSerde(Serdes.Long()) /* serde for aggregate value */
KGroupedStream
- input record들 중에서 키 값이 널인 경우는 무시한다.
- 해당 Key에 대한 Record가 처음으로 온 경우에만 Initializer가 호출된다. (이는 adder를 호출하기 전에 호출된다)
- 새로운 Record를(Value가 널이 아닌 경우) 받을때마다, adder가 호출된다.
KGroupedTable
- input record들 중에서 키 값이 널인 경우는 무시한다.
- 해당 Key에 대한 Record가 처음으로 온 경우에는 Initializer가 호출된다. (이는 adder와 subtractor를 호출하기 전에 호출된다) KGroupedStream과는 다르게 키에 대한 Record가 삭제 된 경우에 Initializer가 한 번 이상 호출될 수 있다.
- 해당 Key에 대한 value가 널이 아닌 record를 처음으로 받은 경우에는, adder만 호출된다. (INSERT)
- 이미 한 번 받은 키에 해당하는 record 차례로 들어오는 경우에는 subtractor와 adder가 모두 호출이된다. 이 때 subtractor에는 테이블에 저장된 이전 값이 전달되며, adder는 새로운 값이 전달된다. (UPDATE)
- value가 널인 record는 해당 Key에 대해서 삭제하라는 표시이다. 이 경우에는 subtractor만 호출이 된다. 만약에 subtractor에서 널을 리턴하는 경우, 해당 키에 대한 Record는 KTable에서 삭제된다. Record가 삭제된 경우 해당 Key에 대한 Record를 다시 수신하는 경우에 Initializer를 호출한다.
Joining
Stream과 table은 조인을 할 수 있다. 실제로 많은 스트림 프로세싱 어플리케이션이 스트림 조인을 사용한다. 예를 들어 온라인 쇼핑몰 서비스는 한번에 여러개의 데이터베이스 테이블(상품 테이블, 재고 테이블, 회원 테이블 등)에 액세스해야 하는 경우가 있다. 그리고 이러한 조회가 대규모로 일어나고, 매우 낮은 latency를 가져야하는 경우엔 데이터베이스의 조인 쿼리로는 한계가 있을 수 있다. 이런 경우에 사용할 수 있는 패턴이 Kafka’s Connect API를 사용하는 것이다. Connect API를 사용해서 데이터베이스의 변경된 데이터를 카프카로 전송한다. 이를 통해 데이터베이스에 있는 데이터를 카프카에서 사용할 수 있다. 그리고나서 Streams API를 사용해서 매우 빠르고 효율적인 로컬 조인을 수행하는 어플리케이션을 개발한다. 이러면 어플리케이션은 원하는 데이터를 조회하기 위해서 데이터베이스에 조인 쿼리를 수행하지 않아도 된다. 이 예에서 Kafka Streams의 KTable 개념을 사용하면 각 테이블의 최신 상태를 로컬 State Store에 저장할 수 있다. 따라서 이러한 스트림 조인을 통해 원격 데이터베이스의 부하를 줄일 수 있으며, latency를 크게 줄일 수 있다.
아래와 같은 조인 연산이 지원된다. 어떤 것들의 조인하느냐에 따라서 조인은 windowed 조인과 non-windowed 조인으로 나뉜다.
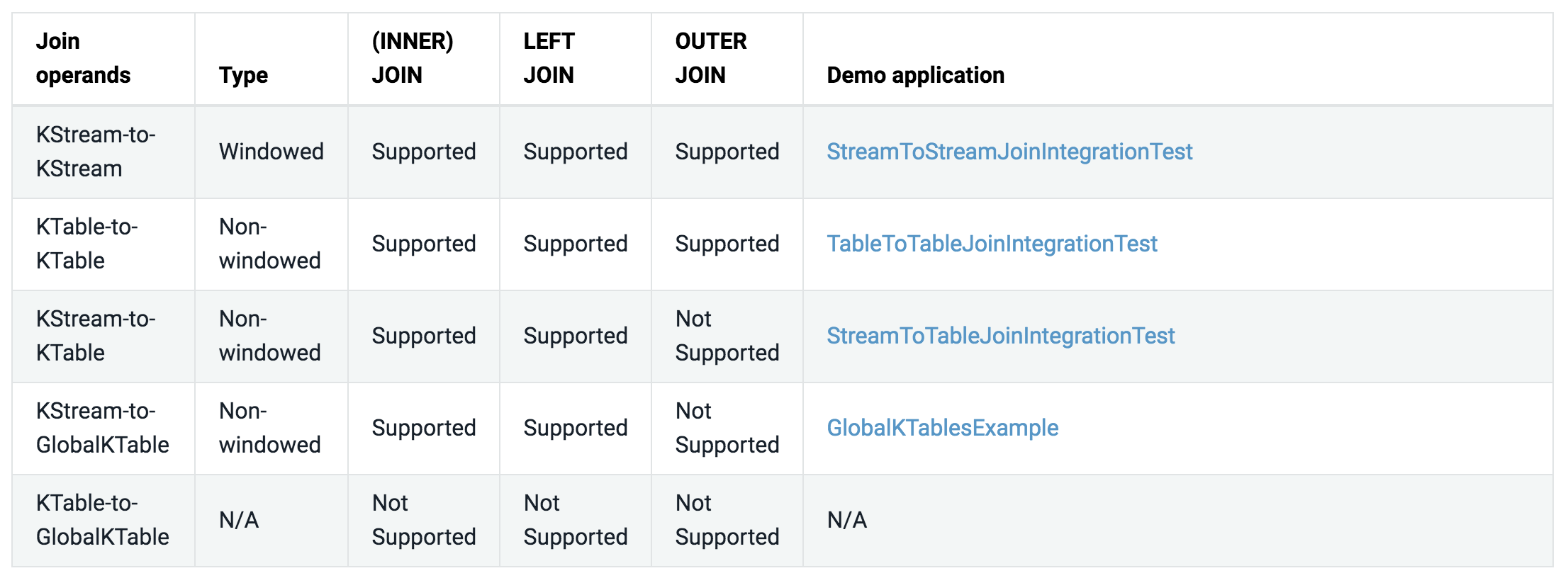
Join co-partitioning requirements
조인을 할 때 입력 데이터는 반드시 co-partitioning 되어야한다. 이는 같은 키를 가진 입력 레코드는 같은 태스크로 전달되는 것을 보장해준다. 조인을 할 때 co-partitioning을 보장하는 것은 개발자의 책임이다.
- 가능하다면 조인을 할 때 global tables를 사용해라. 왜냐하면 global tables는 co-partitioning을 요구하지 않는다.
co-partitioning이 요구하는 사항은 아래와 같다.
- input 토픽은 같은 수의 파티션을 가져야한다.
- input 토픽에 레코드를 전송하는 어플리케이션은 반드시 같은 partitioning strategy를 사용해야 한다. 이를 통해 같은 키를 가진 레코드는 반드시 같은 파티션으로 전달되어야한다. 즉 조인 하려는 토픽은 같은 방식으로 레코드를 파티션에 분산시켜야 한다. 따라서 자바 KafkaProducer를 사용하는 경우 반드시 같은 partitioner를 사용해야한다. 또한 Kafka Streams API를 사용하는 경우에는 반드시 같은 StreamPartitioner를 사용해야 한다. 다행히도 모든 어플리케이션이 디폴트 partitioner를 사용하고 있다면, partitioning strategy에 대해 걱정할 필요가 없다.
co-partitioning가 왜 필요한 것일까? 왜냐하면 KStream-KStream, KTable-KTable, 그리고 KStream-KTable 조인은 레코드의 키를 기반으로 조인을 수행하기 때문이다. 유일한 예외가 KStream-GlobalKTable 조인이다. 이 경우에는 co-partitioning이 필요하지 않다. 왜냐하면 GlobalKTable은 모든 파티션에 대한 changelog stream이기 때문이다. 또한 KeyValueMapper를 사용하면 KStream과 GlobalKTable을 키 기반이 아닌 조인을 수행할 수 있다.
- Kafka Streams는 co-partitioning을 부분적으로 검증한다. 파티션 할당 단계에서, 즉 런타임에서, Kafka Streams는 조인하려는 토픽의 파티션수가 같은지를 확인한다. 만약에 같지 않다면 TopologyBuilderException이 발생한다. Kafka Streams는 partitioning strategy가 같은지를 검증할 수는 없다. 따라서 개발자가 이를 보장해야한다.
Ensuring data co-partitioning
조인의 입력이 co-partitioning되지 않았다면, 수동으로 이를 보장해야 한다. 이를 위해서는 Kafka Streams API - Ensuring data co-partitioning를 참고하길 바란다. 이 과정을 요약하자면 조인하려는 토픽중 파티션 개수가 작은 토픽을 위한 중간 토픽을 만드는 것이다. 중간 토픽을 만들때 조인하려는 토픽중 파티션 개수가 큰 토픽에 파티션수를 맞춘다. 그리고 같은 Partitioner를 사용해서 작은 토픽의 레코드들을 중간 토픽으로 복사한다. 그리고 중간 토픽과 큰 토픽을 조인한다. 중간 토픽의 파티션 개수는 큰 토픽과 같기 때문에 조인이 가능하다.
KStream-KStream Join
KStream-KStream 조인은 항상 windowed 조인이다. 그렇지 않으면 조인을 수행하기 위한 내부 State Store의 크기는 무한정으로 증가할 것이다. 스트림 조인의 경우 한 토픽의 새로운 레코드가 다른 토픽의 매칭되는 레코드와 조인되어 결과를 생성한다. 이 때 매칭되는 레코드는 주어진 윈도우내에서 여러개일 수 있다.
ValueJoiner를 사용해서 조인 결과 레코드가 생성된다.
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
inner join
다른 스트림과 inner 조인을 수행할 수 있다. 윈도우 연산임에도 불구하고 조인의 결과는 Kstream<K, …>이 된다. 조인 대상이 되는 스트림은 반드시 co-partitioning 해야한다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다. (둘 다 표시된 경우에는 둘 다 re-partitioning 된다)
import java.util.concurrent.TimeUnit;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(TimeUnit.MINUTES.toMillis(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
세부 동작
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 조인은 윈도우 기반이다. 두 개 레코드의 타임스탬프 차이가 JoinWindows 보다 작은 경우에만 조인을 수행한다. 윈도우는 타임스탬프에 대한 추가적인 조인 조건을 정의한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키나 value가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
left join
다른 스트림과 left join을 수행할 수 있다. 윈도우 연산임에도 불구하고 조인의 결과는 Kstream<K, …>이 된다. 조인 대상이 되는 스트림은 반드시 co-partitioning 해야한다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다. (둘 다 표시된 경우에는 둘 다 re-partitioning 된다)
import java.util.concurrent.TimeUnit;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(TimeUnit.MINUTES.toMillis(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
세부 동작
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 조인은 윈도우 기반이다. 두 개 레코드의 타임스탬프 차이가 JoinWindows 보다 작은 경우에만 조인을 수행한다. 윈도우는 타임스탬프에 대한 추가적인 조인 조건을 정의한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키나 value가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
- 왼쪽 스트림의 input 레코드와 매칭되는 오른쪽 스트림 레코드가 없는 경우에는, ValueJoiner.apply 메소드의 두번째 인자로 null이 들어간다.
outer join
다른 스트림과 outer join을 수행할 수 있다. 윈도우 연산임에도 불구하고 조인의 결과는 Kstream<K, …>이 된다. 조인 대상이 되는 스트림은 반드시 co-partitioning 해야한다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다. (둘 다 표시된 경우에는 둘 다 re-partitioning 된다)
import java.util.concurrent.TimeUnit;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.outerJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(TimeUnit.MINUTES.toMillis(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
세부 동작
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 조인은 윈도우 기반이다. 두 개 레코드의 타임스탬프 차이가 JoinWindows 보다 작은 경우에만 조인을 수행한다. 윈도우는 타임스탬프에 대한 추가적인 조인 조건을 정의한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키나 value가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
- 새로운 레코드를 받았을 때, 반대쪽 스트림에 매칭되는 레코드가 없는 경우에는 ValueJoiner.apply 메소드에 첫번째 혹은 두번째 인자에 null이 들어간다. (ValueJoiner#apply(leftRecord.value, null) 또는 ValueJoiner#apply(null, rightRecord.value)) Left 조인과 달리 ValueJoiner#apply(null, rightRecord.value)이 가능하다.
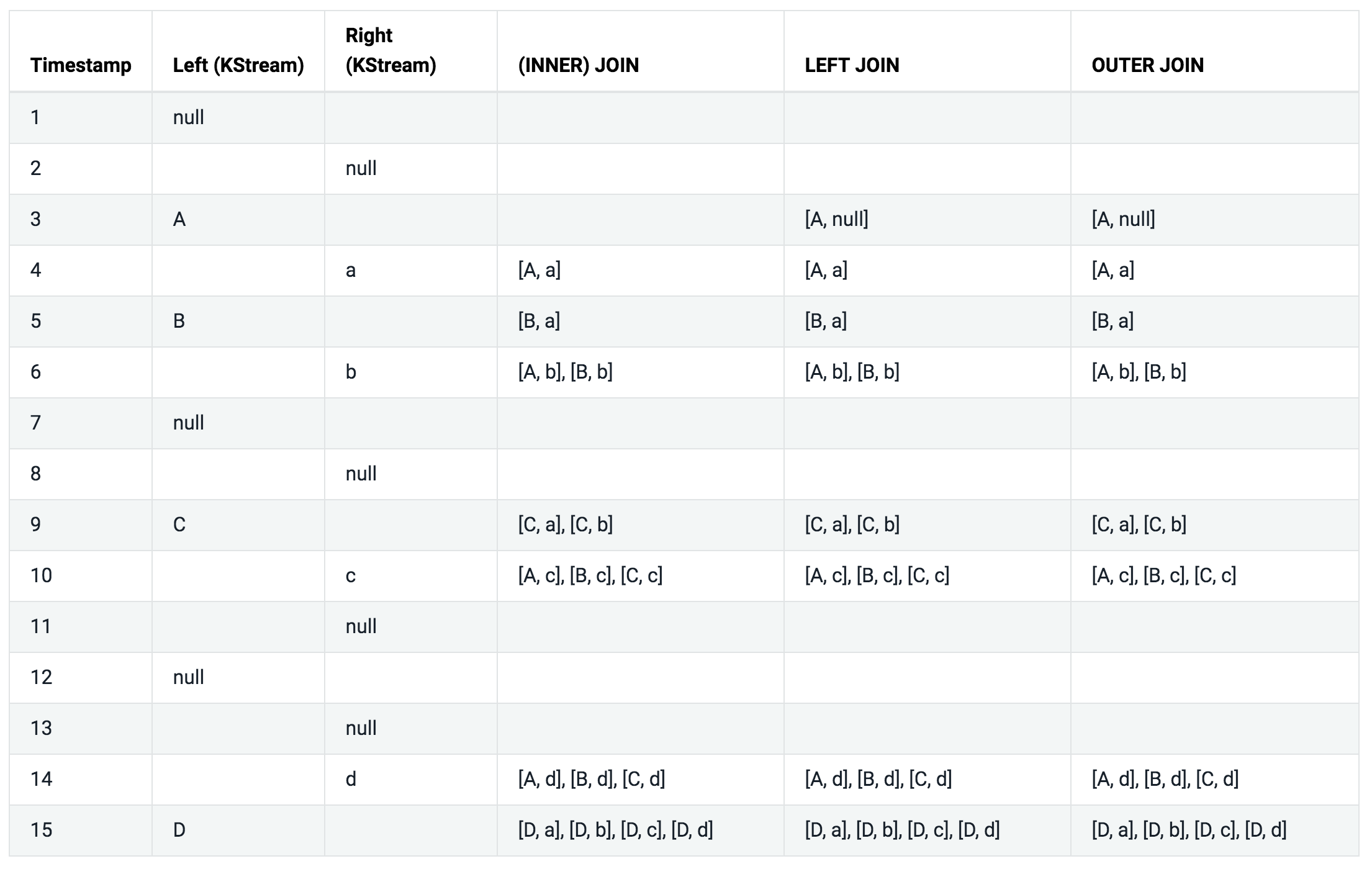
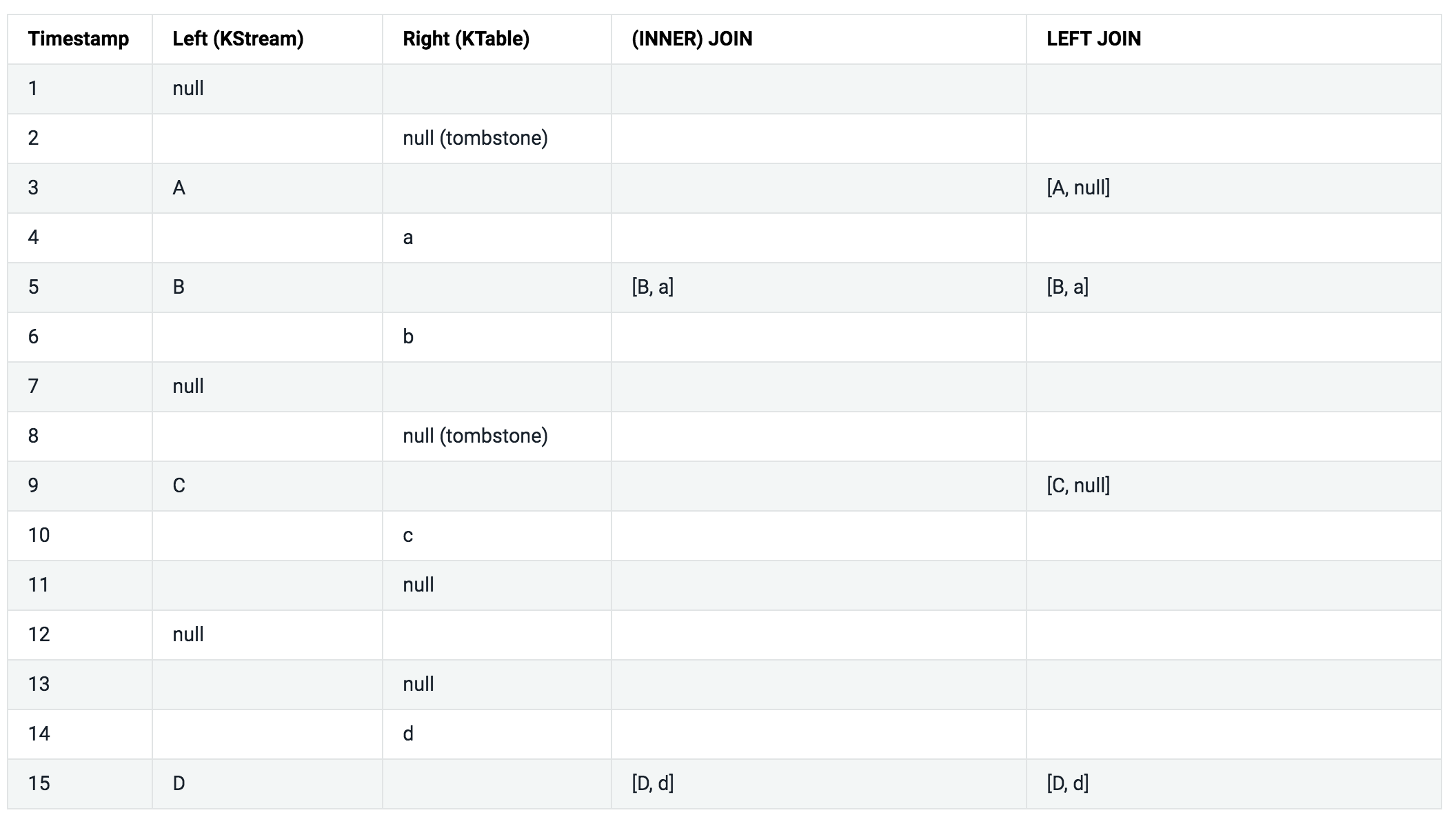
Semantics of stream-stream joins:
아래 테이블을 좀 더 쉽게 설명하기 위해서 아래와 같은 가정을 했다.
- 모든 레코드는 같은 키를 가지고 있다.
- 모든 레코드는 같은 조인 윈도우에 속한다.
- 모든 레코드들은 타임스탬프 순으로 처리된다.
INNER JOIN, LEFT JOIN, OUTER JOIN 칼럼은 ValueJoiner#apply 메소드의 파리미터로 어떤 값이 전달되었는지를 나타낸다.
KTable-KTable Join
KTable-KTable 조인은 윈도우 조인이 아니다. 조인 결과는 KTable이며 조인 연산의 changelog 스트림이다.
아래는 간단한 샘플 코드이다. 사용자는 ValueJoiner를 제공해야 하며, ValueJoiner를 사용해서 조인 연산을 수행한다.
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
inner join (KTable, KTable) → KTable
두 개의 KTable을 inner 조인할 수 있다. 조인 결과는 KTable이며 조인 연산의 가장 최신 결과를 나타낸다. 조인 대상이 되는 KTable은 반드시 co-partitioning 해야한다.
KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
- value가 널인 레코드는 해당 키에 대한 삭제표시이다. 이는 테이블에서 해당 키가 삭제되었음을 의미한다. 삭제표시는 조인을 트리거하지는 않는다. input으로 value가 널인 레코드를 받으면, 조인 결과 KTable에 전달된다. (단 조인 결과 KTable에 해당 키가 이미 존재할 경우)
left join
두 개의 KTable을 left 조인할 수 있다. 조인 결과는 KTable이며 조인 연산의 가장 최신 결과를 나타낸다. 조인 대상이 되는 KTable은 반드시 co-partitioning 해야한다.
KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
- value가 널인 레코드는 해당 키에 대한 삭제표시이다. 이는 테이블에서 해당 키가 삭제되었음을 의미한다. 삭제표시는 조인을 트리거하지는 않는다. input으로 value가 널인 레코드를 받으면, 조인 결과 KTable에 전달된다. (단 조인 결과 KTable에 해당 키가 이미 존재할 경우)
- 왼쪽 input 레코드와 매칭되는 오른쪽 레코드가 없는 경우에는, ValueJoiner.apply 메소드의 두번째 인자로 null이 들어간다.
outer join
두 개의 KTable을 outer 조인할 수 있다. 조인 결과는 KTable이며 조인 연산의 가장 최신 결과를 나타낸다. 조인 대상이 되는 KTable은 반드시 co-partitioning 해야한다.
KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.outerJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 키가 널인 레코드는 무시된다. 그리고 조인을 트리거하지 않는다.
- value가 널인 레코드는 해당 키에 대한 삭제표시이다. 이는 테이블에서 해당 키가 삭제되었음을 의미한다. 삭제표시는 조인을 트리거하지는 않는다. input으로 value가 널인 레코드를 받으면, 조인 결과 KTable에 전달된다. (단 조인 결과 KTable에 해당 키가 이미 존재할 경우)
- 새로운 레코드를 받았을 때, 반대쪽 스트림에 매칭되는 레코드가 없는 경우에는 ValueJoiner.apply 메소드에 첫번째 혹은 두번째 인자에 null이 들어간다. (ValueJoiner#apply(leftRecord.value, null) 또는 ValueJoiner#apply(null, rightRecord.value)) Left 조인과 달리 ValueJoiner#apply(null, rightRecord.value)이 가능하다.
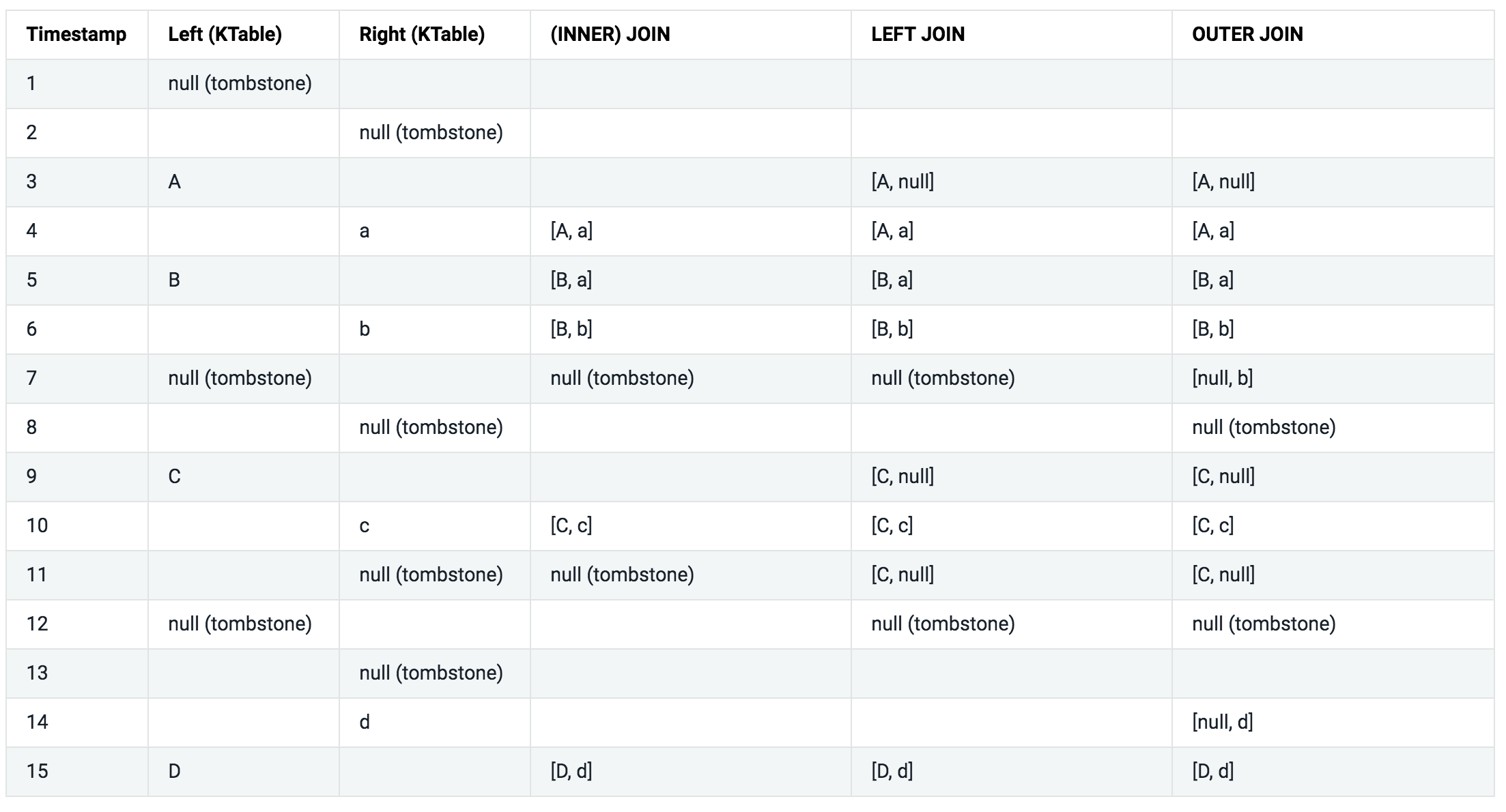
Semantics of stream-table joins
아래 테이블을 좀 더 쉽게 설명하기 위해서 아래와 같은 가정을 했다.
- 모든 레코드는 같은 키를 가지고 있다.
- 모든 레코드들은 타임스탬프 순으로 처리된다.
INNER JOIN, LEFT JOIN, OUTER JOIN 칼럼은 ValueJoiner#apply 메소드의 파리미터로 어떤 값이 전달되었는지를 나타낸다.
KStream-KTable Join (KStream, KTable) → KStream
KStream-KTable 조인은 윈도우 조인이 아니다. KStream이 새로운 레코드를 받으면, KTable의 데이터를 조회해볼 수 있다. 예를 들어 최신 사용자 프로필 정보(KTable)을 이용해서 사용자 활동 스트림(KStream)을 더욱 풍부하게 하는 것이다.
사용자가 제공한 ValueJoiner를 사용해서 조인을 수행한다.
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
inner join
스트림과 테이블을 inner 조인할 수 있다. 조인 대상이 되는 KStream, KTable은 반드시 co-partitioning 해야한다. Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다.
KStream<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 오로지 스트림의 input 레코드만 조인을 트리거한다. 테이블의 input 레코드는 테이블을 업데이트하기만 한다.
- 스트림의 input 레코드의 키 혹은 value가 널인 경우에는 무시된다.
- 테이블의 input 레코드의 value가 널인 경우 해당 키에 대한 삭제 표시로 해석된다. 이는 테이블에서 해당 키의 데이터가 삭제되었음을 의미한다. 삭제표시는 조인을 트리거하지 않는다.
- 왼쪽 input 레코드와 매칭되는 오른쪽 레코드가 없는 경우에는, ValueJoiner.apply 메소드의 두번째 인자로 null이 들어간다.
left join
스트림과 테이블을 left 조인할 수 있다. 조인 대상이 되는 KStream, KTable은 반드시 co-partitioning 해야한다. Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다.
KStream<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
- 조인은 키 기반이다. leftRecord 키와 rightRecord 키가 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 오로지 스트림의 input 레코드만 조인을 트리거한다. 테이블의 input 레코드는 테이블을 업데이트하기만 한다.
- 스트림의 input 레코드의 키 혹은 value가 널인 경우에는 무시된다.
- 테이블의 input 레코드의 value가 널인 경우 해당 키에 대한 삭제 표시로 해석된다. 이는 테이블에서 해당 키의 데이터가 삭제되었음을 의미한다. 삭제표시는 조인을 트리거하지 않는다.
- 왼쪽 input 레코드와 매칭되는 오른쪽 레코드가 없는 경우에는, ValueJoiner.apply 메소드의 두번째 인자로 null이 들어간다.
Semantics of stream-table joins
KStream-GlobalKTable Join (KStream, GlobalKTable) → KStream
KStream-GlobalKTable 조인은 윈도우 조인이 아니다. KStream에서 새로운 레코드를 받으면, GlobalKTable의 데이터를 조회해볼 수 있다.
KStream-GlobalKTable 조인은 KStream-KTable 조인과 매우 유사하다. 그러나 글로벌 테이블은 약간의 비용으로 훨씬 더 많은 유연성을 제공한다.
- data co-partitioning을 요구하지 않는다.
- 외래키 조인이 가능하다. 스트림의 레코드 키 뿐만 아니라 레코드 value의 데이터를 사용하여 테이블의 데이터를 조회 할 수 있다.
- 많은 유스 케이스를 실현 가능하게 만든다.
- 연속적으로 여러 조인을 수행해야 할 때 KTable보다 효율적이다.
사용자가 제공한 ValueJoiner를 사용해서 조인을 수행한다.
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
inner join
스트림과 global 테이블을 inner 조인할 수 있다. GlobalKTable은 KafkaStreams 객체가 시작될 때 초기화된다. 이는 테이블이 토픽의 모든 데이터로 완전히 채워졌음을 의미한다. 실제 데이터 처리는 테이블의 초기화 작업이 완료된 후에 시작된다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다.
KStream<String, Long> left = ...;
GlobalKTable<Integer, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftKey, leftValue) -> leftKey.length(), /* derive a (potentially) new key by which to lookup against the table */
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
상세 설명
- 조인은 간접적인 키 기반이다. KeyValueMapper#apply(leftRecord.key, leftRecord.value)의 결과가 rightRecord.key와 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 오로지 스트림의 input 레코드만 조인을 트리거한다. 테이블의 input 레코드는 테이블을 업데이트하기만 한다.
- 스트림의 input 레코드의 키 혹은 value가 널인 경우에는 무시된다.
- 테이블의 input 레코드의 value가 널인 경우 해당 키에 대한 삭제 표시로 해석된다. 이는 테이블에서 해당 키의 데이터
left join
스트림과 global 테이블을 left 조인할 수 있다. GlobalKTable은 KafkaStreams 객체가 시작될 때 초기화된다. 이는 테이블이 토픽의 모든 데이터로 완전히 채워졌음을 의미한다. 실제 데이터 처리는 테이블의 초기화 작업이 완료된 후에 시작된다.
Stream이 re-partition되어야 한다고 표시된 경우에만 re-partitioning한다.
KStream<String, Long> left = ...;
GlobalKTable<Integer, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftKey, leftValue) -> leftKey.length(), /* derive a (potentially) new key by which to lookup against the table */
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
상세 설명
- 조인은 간접적인 키 기반이다. KeyValueMapper#apply(leftRecord.key, leftRecord.value)의 결과가 rightRecord.key와 같은 경우에 조인을 수행한다.
- 새로운 레코드을 받을때마다, 아래 나열된 조건하에 조인이 트리거된다. 조인이 트리거되면, 유저가 제공한 ValueJoiner가 호출된다. ValueJoiner는 조인 결과 레코드를 리턴한다.
- 오로지 스트림의 input 레코드만 조인을 트리거한다. 테이블의 input 레코드는 테이블을 업데이트하기만 한다.
- 스트림의 input 레코드의 키 혹은 value가 널인 경우에는 무시된다.
- 테이블의 input 레코드의 value가 널인 경우 해당 키에 대한 삭제 표시로 해석된다. 이는 테이블에서 해당 키의 데이터
- 왼쪽 input 레코드와 매칭되는 오른쪽 레코드가 없는 경우에는, ValueJoiner.apply 메소드의 두번째 인자로 null이 들어간다.
Semantics of stream-table joins
조인 의미는 KStream-KTable 조인과 동일하다. 유일한 차이점은 간접적인 키 기반이라는 것이다. KeyValueMapper#apply(leftRecord.key, leftRecord.value)의 결과로 GlobalKTable를 조회한다.
Windowing
Windowing을 사용하면 aggregation이나 join과 같은 Stateful 연산을 할 때, 같은 key를 가지는 레코드들을 windows라고 불리는 그룹으로 그룹화할 수 있다.
Note 관련된 연산은 grouping이다. grouping은 동일한 키를 가진 레코드들끼리 그룹화한다. 이를 통해서 데이터들이 올바르게 분할되도록한다. 그리고 Windowing 작업을 통해서 그룹을 더 하위 그룹으로 묶을 수 있다.
예를 들어 조인 연산에서 Windowing State Store는 정의된 window 경계 내에서 받은 모든 레코드들을 저장하는데 사용이 된다. 집계 연산에서는 Windowing State Store는 window당 가장 최신의 집계 결과를 저장하는데 사용이 된다.
State Store에 저장된 데이터들은 지정된 window 보존 기간이 지나면 제거된다. Kafka Streams는 window를 최소한 보장 기간 동안 저장한다. 디폴트 값은 1일이며 Windows#until() 혹은 SessionWindows#until() 메소드를 통해서 변경할 수 있다.
추가 내용 Windowing 연산은 Kafka Streams DSL를 통해서 사용할 수 있다. Window 연산을 사용할 때 Window의 보존 기간(retention period)을 명시할 수 있다. 이 보존 기간은 Window가 순서가 잘못된 레코드나 늦게 도착하는 레코드를 얼마나 기다릴 것인지를 결정한다. 만약에 레코드가 Window 보존 기간이 지난 이후에 도착이 했다면 레코드는 해당 window에서 처리되지 않고 버려진다.
Window는 Time Semantics하고도 큰 관련이 있다. Time Semantics에 대한 더 자세한 내용은 Time를 참고하길 바란다.
Window와 Time Semantics 늦게 도착하는 레코드는 실제로 일어날 수 있으며, 어플리케이션에서 적절하게 처리해야 한다. 늦게 도착한 레코드를 어떻게 처리할지는 time semantics에 달려있다. processing time은 레코드가 처리될 때의 시간이다. 따라서 이 경우에는 늦게 도착하는 레코드 개념이 적용되지 않는다. 따라서 늦게 도착하는 레코드 개념은 event-time 혹은 ingestion-time를 사용할 때에만 적용된다. 이 때는 Kafka Streams가 늦게 도착하는 레코드를 적절하게 처리할 수 있다.
DSL은 아래와 같은 Window을 지원한다. 더 자세한 내용은 아래에서 설명하도록 하겠다.
- Tumbling time window : Fixed-size, non-overlapping, gap-less windows
- Hopping time window : Fixed-size, overlapping windows
- Sliding time window : Fixed-size, overlapping windows that work on differences between record timestamps
- Session window : Dynamically-sized, non-overlapping, data-driven windows
Tumbling time windows
Tumbling time windows는 Hopping Time Window의 특별한 케이스이다. Hopping Time Window와 마찬가지로 시간 간격을 기반으로 하는 Window이다. Tumbling time windows는 고정된 크기의 겹치지 않고 간격이 없는 Window를 모델링한다. Tumbling window는 하나의 속성(Window의 크기)으로 정의된다. Tutumbling window는 window size가 advance interval과 동일한 hopping window이다. Tutumbling window는 절대로 겹치지 않는다. 따라서 하나의 레코드는 오직 하나의 Window에만 속한다.

위의 그림은 데이터 레코드 스트림을 Tutumbling window을 사용해서 Windowing한 모습을 보여준다. advance interval과 window size는 동일하기 때문에 Window는 절대로 겹치지 않는다. 위의 다이어그램에서 시간 숫자는 분을 의미한다. 실제로 Kafka Stream에서 시간 단위는 milliseconds이다.
Tutumbling window의 첫번째 Window는 0부터 시작한다. 예를 들어 Tutumbling window의 크기가 5000ms인 경우에는 다음과 같은 Window 경계를 가진다. [0, 5000], [5000, 10000] … 여기서 각 간격의 하위 경계는 간격에 포함되지만 상위 경계는 포함되지 않는다.
아래의 코드는 크기가 5분인 Tutumbling window을 정의한다.
import java.util.concurrent.TimeUnit;
import org.apache.kafka.streams.kstream.TimeWindows;
// A tumbling time window with a size of 5 minutes (and, by definition, an implicit
// advance interval of 5 minutes).
long windowSizeMs = TimeUnit.MINUTES.toMillis(5); // 5 * 60 * 1000L
TimeWindows.of(windowSizeMs);
// The above is equivalent to the following code:
TimeWindows.of(windowSizeMs).advanceBy(windowSizeMs);
아래는 Tutumbling window을 사용한 카운팅 예제이다.
// Key (String) is user id, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per window, per user, with tumbling windows of size 5 minutes
KTable<Windowed<String>, Long> windowedPageViewCounts = pageViews
.groupByKey(Serialized.with(Serdes.String(), genericAvroSerde))
.windowedBy(TimeWindows.of(TimeUnit.MINUTES.toMillis(5)))
.count();
Hopping time windows
Hopping time windows는 시간 간격을 기반으로 한 Window이다. Hopping time windows는 고정된 크기의 겹치는 Window들을 모델링 한다. Hopping Window는 Window의 크기와 advance interval (hop이라고도 함) 속성으로 정의된다. advance interval은 이전 Window와 비교해서 Window가 앞으로 얼마나 움직일지를 결정한다. Hopping window는 겹칠 수 있으므로 하나의 레코드가 하나 이상의 Window에 속하게 된다.
다음의 코드는 윈도우의 크기가 5분이며 advance interval이 1분인 hopping window를 정의한다.
import java.util.concurrent.TimeUnit;
import org.apache.kafka.streams.kstream.TimeWindows;
// A hopping time window with a size of 5 minutes and an advance interval of 1 minute.
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
long windowSizeMs = TimeUnit.MINUTES.toMillis(5); // 5 * 60 * 1000L
long advanceMs = TimeUnit.MINUTES.toMillis(1); // 1 * 60 * 1000L
TimeWindows.of(windowSizeMs).advanceBy(advanceMs);

위의 그림은 데이터 레코드 스트림을 Hopping window을 사용해서 Windowing한 모습을 보여준다.
Hopping time windows의 첫번째 윈도우는 0부터 시작한다. 예를 들어 윈도우의 크기가 5000ms이고 advance interval이 3000ms인 hopping windows는 다음과 같은 윈도우 경계를 가진다. [0;5000], [3000;8000] … 여기서 각 간격의 하위 경계는 간격에 포함되지만 상위 경계는 포함되지 않는다.
다음은 Hopping windows의 간단한 예제이다.
// Key (String) is user id, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per window, per user, with hopping windows of size 5 minutes that advance every 1 minute
KTable<Windowed<String>, Long> windowedPageViewCounts = pageViews
.groupByKey(Serialized.with(Serdes.String(), genericAvroSerde))
.windowedBy(TimeWindows.of(TimeUnit.MINUTES.toMillis(5).advanceBy(TimeUnit.MINUTES.toMillis(1))))
.count()
윈도우를 사용한 집계는 windowed KTable을 반환한다. windowed KTable는 키의 타입이 Windowed<K>인 KTable을 말한다. 이는 다른 Window들끼리 같은 키에 대한 집계 결과를 구별하기 위해서이다. Windowed#key()를 통해서 실제 키 값을 얻을 수 있으며 Windowed#window()를 통해서 Window 객체를 얻을 수 있다.
Sliding time windows
Sliding windows는 hopping, tumbling windows와는 많이 다르다. Kafka Streams에서 Sliding Window는 조인 연산에서만 사용된다. 그리고 JoinWindows 클래스의 스태틱 메소드을 통해서 JoinWindows 객체를 생성할 수 있다.
Sliding windows는 시간 축을 따라 계속 슬라이드하는 고정된 크기의 Window를 모델링한다. 만약 2개 레코드의 타임 스탬프 차이가 window size보다 작은 경우에는, 2개의 레코드가 같은 Window에 포함된다. Sliding windows의 첫번째 Window는 0부터 시작하지 않는다. 그리고 Sliding windows의 윈도우 간격은 하위 경계와 상위 경계를 모두 포함한다.
Session Windows
Session Windows는 키 기반의 이벤트를 session으로 집계하는데 사용된다. 이러한 과정을 sessionization이라고 부른다. 세션은 activity 기간을 나타내며 activity 기간은 inactivity 간격에 의해서 분리된다. 이벤트가 기존 세션의 inactivity 간격안에 들어오는 경우 기존 세션에 병합된다. 만약 이벤트가 기존 세션의 inactivity 간격을 벗어난 경우엔 새로운 세션을 생성한다.
Session Windows는 다른 Window와 아래와 같은 차이가 있다.
- 모든 Window는 키를 통해 독립적으로 추적된다. 레코드의 키가 다른 윈도우는 일반적으로 시작 및 종료 시간이 다르다.
- Session Windows의 크기는 다양하다. 심지어 동일한 키에 대한 Window의 크기도 일반적으로 다르다.
Session Window는 주로 사용자의 행동을 분석하는데 사용된다. 아래의 코드는 inactivity 간격이 5분인 Session Window를 생성한다.
import java.util.concurrent.TimeUnit;
import org.apache.kafka.streams.kstream.SessionWindows;
// A session window with an inactivity gap of 5 minutes.
SessionWindows.with(TimeUnit.MINUTES.toMillis(5));
간단한 예를 통해서 설명을 하도록 하겠다. SessionWindow의 inactivity의 간격이 5분이고 6개의 레코드가 들어오는 경우 아래와 같이 세션이 생성된다.
6개의 레코드 중에서 3개의 레코드가 먼저 들어왔다고 가정해보자. 그러면 아래와 같이 3개의 세션이 생성될 것이다.
- 녹색 레코드 키 : 세션이 0분에서 시작되고 0분에서 끝난다.
- 녹색 레코드 키 : 세션이 6분에서 시작되고 6분에서 끝난다.
- 파랑색 레코드 키 : 세션이 2분에서 시작되고 2분에서 끝난다.
아래의 그림은 3개의 세션이 생성된 상태를 나타낸다.

그 다음에 3개의 레코드가 추가적으로 들어왔다고 가정해보자. 녹색 레코드 키에 대한 2개의 기존 세션이 단일 세션으로 병합된다. 병합된 세션은 0에서 시작되어 6에서 끝나며 총 3개의 레코드로 구성된다. 파란색 레코드 키에 대한 기존 세션은 확장되어 2에서 시작되어 5에서 끝난다. 그리고 총 2개의 레코드로 구성된다. 그리고 11에서 시작하고 11에서 끝나는 파랑색 레코드 키에 대한 새로운 세션이 생성된다.
아래의 그림은 3개의 레코드가 추가적으로 들어온 뒤에 세션의 모습이다. 늦게 도착한 녹색 레코드(t=4)는 기존 세션을 병합하고, 늦게 도착한 파랑색 레코드(t=5)는 기존 세션을 확장시킨다.

아래의 코드는 session windows를 사용한 카운팅 예제이다. 뉴욕 타임즈와 같은 뉴스 웹 사이트에서 독자의 행동을 분석하려고 한다고 가정하자. 한 사람이 5분 지나기 전에 다른 페이지를 클릭하는 경우(=inactivity gap), 이것을 한 번의 방문으로 간주하여 그 사람의 연속적인 reading session으로 간주한다. 이 입력 데이터 스트림에서 계산하려는 것은 session 당 페이지 뷰 수이다.
// Key (String) is user id, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per session, per user, with session windows that have an inactivity gap of 5 minutes
KTable<Windowed<String>, Long> sessionizedPageViewCounts = pageViews
.groupByKey(Serialized.with(Serdes.String(), genericAvroSerde))
.windowedBy(SessionWindows.with(TimeUnit.MINUTES.toMillis(5))
.count();
Applying Processors and transformers (Processor API integration)
StreamDSL은 Staless나 Stateful Operation 외에도 DSL 안에서 직접 Processor API를 활용할 수 있다. 직접 Processor API를 사용할 필요가 있는 시나리오는 다음과 같다,
- Customization : DSL에서 제공하지 않는 특별한 로직을 구현할 필요가 있는 경우
- Combining ease-of-use with full flexibility where it’s needed : DSL이 제공하는 것보다 더 많은 유연성과 조정이 필요한 경우가 있다. 예를 들어 오직 Processor API만 Record의 메타데이터를 제공한다. 그러나 메타데이터를 얻기 위해서 Processor API로 완전히 전환할 필요는 없다.
Process
- KStream -> Void
Terminal Operation이다. 각각의 Record는 Processor에 의해 처리된다. process()를 사용하면 DSL에서 Processor API를 사용할 수 있도록 해준다. 더 자세한 사항은 details를 참고해라 사실 process 메소드는 Topology#addProcessor()를 통해서 프로세서 Topology에 Processor를 추가하는 것과 같다.
Transform
- KStream -> KStream
각각의 Record에 Transformer를 적용한다. transform() 메소드를 통해서 DSL에서 Processor API를 사용할 수 있다. 각각의 input 레코드는 0개 이상의 output 레코드로 변환된다. (flatMap과 유사하다) Transformer에서 널을 리턴하는 경우는 output 레코드가 0개가 된다. input 레코드의 키와 value의 값과 타입을 변경할 수 있다.
tranform 메소드 이후에 grouping 혹은 join을 하는 경우에는 레코드의 re-partitioning이 일어날 수 있다. 가능하면 transformValues를 사용해라. transformValues는 re-partitioning을 유발하지 않는다.
transform은 기본적으로 Topology.addProcessor를 통해서 Transformer를 프로세서 Topology에 추가하는 것과 같다.
Transform (Values Only)
- KStream -> KStream
각각의 Record에 ValueTransformer를 적용한다. 이 때 키는 그대로 유지된다. transformValues()를 사용하면 DSL에서 Processor API를 사용할 수 있다. 각각의 input record들은 정확히 하나의 output record로 변환되어야 한다. (0개의 output 혹은 2개 이상의 output은 불가능하다) ValueTransformer에서 널을 리턴할 수는 있다. (이 경우 output record의 value는 널이 된다)
transformValues는 데이터 re-partitioning이 일어나지 않기 때문에 가능하면 transformValues를 사용해라. transformValues는 기본적으로 Topology.addProceesor()를 통해서 ValueTransformer를 프로세서 Topology에 추가하는 것과 같다.
Example
다음 예제는 KStream의 process 메소드와 커스텀 Processor를 사용해서 페이지 뷰 카운트가 특정 임계값에 도달하면 이메일 알림을 보내는 예제이다.
우선 Custom Processor의 구현이 필요하다. PopularPageEmailAlert 클래스는 Processor 인터페이스를 구현하고 있다.
// A processor that sends an alert message about a popular page to a configurable email address
public class PopularPageEmailAlert implements Processor<PageId, Long> {
private final String emailAddress;
private ProcessorContext context;
public PopularPageEmailAlert(String emailAddress) {
this.emailAddress = emailAddress;
}
@Override
public void init(ProcessorContext context) {
this.context = context;
// Here you would perform any additional initializations such as setting up an email client.
}
@Override
void process(PageId pageId, Long count) {
// Here you would format and send the alert email.
//
// In this specific example, you would be able to include information about the page's ID and its view count
// (because the class implements `Processor<PageId, Long>`).
}
@Override
void close() {
// Any code for clean up would go here. This processor instance will not be used again after this call.
}
}
Processor는 ProcessorContext#getStateStore() 메소드를 통해서 State Store에 접근할 수도 있다. 이 때 KStream#process 메소드의 파라미터로 전달된 이름의 State Store에만 접근할 수 있다. 또한 global State Store에도 접근할 수 있다. global State Store의 이름은 KStream#process 메소드 파라미터로 전달되지 않아도 된다. 하지만 global state store는 읽기만 가능하다.
그러면 KStream#process 메소드를 통해서 PopularPageEmailAlert 프로세서를 사용할 수 있다.
KStream<String, GenericRecord> pageViews = ...;
// Send an email notification when the view count of a page reaches one thousand.
pageViews.groupByKey()
.count()
.filter((PageId pageId, Long viewCount) -> viewCount == 1000)
// PopularPageEmailAlert is your custom processor that implements the
// `Processor` interface, see further down below.
.process(() -> new PopularPageEmailAlert("alerts@yourcompany.com"));
TransformerSupplier
KStream#transform 메소드의 첫번째 인자로는 TransformerSupplier 인터페이스의 구현체를 제공해야 한다. 인터페이스는 아래와 같다
**
* A TransformerSupplier interface which can create one or more Transformer instances.
*
* @param <K> key type
* @param <V> value type
* @param <R> {@link org.apache.kafka.streams.KeyValue KeyValue} return type (both key and value type can be set
* arbitrarily)
*/
public interface TransformerSupplier<K, V, R> {
Transformer<K, V, R> get();
}
get 메소드는 Transformer 객체를 생성해서 반환한다.
Transformer<K, V, R>
Transformer 인터페이스는 input 레코드를 0개 혹은 1개 이상의 새로운 output 레코드로 상태 기반으로 매핑할 때 사용한다. 이 때 키와 value의 타입은 변할 수 있다. 이것은 레코드별 stateful operation이다. transform() 메소드는 스트림의 각각에 레코드에 대해 개별적으로 호출된다. 또한 State에 접근하고 수정할 수 있다. 만약에 value값만 변환되어야 한다면 ValueTransformer를 사용해라
Transformer 인터페이스에 존재하는 메소드는 다음과 같다.
- init(ProcessorContext context) : transformer를 초기화한다. 이 메소드는 topology가 초기화 될 때 한번만 호출된다. 제공되는 context 객체는 topology에 접근하기 위해서 사용된다. 또한 context 객체를 통해서 record의 meta data에 접근할 수 있다. 또한 context 객체를 통해서 State Store에 접근할 수 있다. ProcessorContext는 백그라운에서 현재 record의 메타데이터로 업데이트 된다. 따라서 transform 메소드에서 ProcessorContext 객체에 접근하면 항상 올바른 메타데이터를 가지고 있다.
- transform : 주이진 key와 value로 transform한다. 추가적으로 ProcessorContext의 getStateStore 메소드를 통해서 State를 조회하고 수정할 수 있다. 만약에 2개 이상의 output record가 다운스트림으로 전송되어야 한다면, ProcessorContext.forward(Object, Object), ProcessorContext.forward(Object, Object, int), ProcessorContext.forward(Object, Object, String) 메소드를 사용하면 된다. 만약에 record가 다운스트림으로 전송되면 안되는 경우에는 널을 리턴하면 된다.
- punctuate : Deprecated 되었다.
- close : 해당 프로세서를 close한다. 그리고 관련된 리소스를 정리한다.
더 자세한 내용은 Java Docs를 참고해라
KStream#transform(TransformerSupplier<? super K,? super V,KeyValue<K1,V1» transformerSupplier, String… stateStoreNames)
Type Parameters:
- K1 - 새로운 스트림의 Key 타입
- V1 - 새로운 스트림의 Value 타입
각각의 input record를 0개 혹은 1개 이상의 output record로 transform 한다. (키와 value 타입도 변환될 수 있다) Transformer는 각각의 input record에 적용된다. 그리고 0개 혹은 1개 이상의 output records를 생성한다. 따라서 하나의 input record <K, V>는 <K1, V1>, <K2, V2>로 변환될 수 있다. 이는 stateful한 operation이다. 아래는 간단한 샘플 코드이다.
// create store
StoreBuilder<KeyValueStore<String,String>> keyValueStoreBuilder =
Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore("myTransformState"),
Serdes.String(),
Serdes.String());
// register store
builder.addStateStore(keyValueStoreBuilder);
KStream outputStream = inputStream.transform(new TransformerSupplier() { ... }, "myTransformState");
Transformer 객체 안에서 State Store는 ProcessorContext를 통해서 접근할 수 있다. Transformer의 transform() 메소드에서는 반드시 KeyValue 타입을 리턴해야 한다.
new TransformerSupplier() {
Transformer get() {
return new Transformer() {
private ProcessorContext context;
private StateStore state;
void init(ProcessorContext context) {
this.context = context;
this.state = context.getStateStore("myTransformState");
// punctuate each 1000ms; can access this.state
// can emit as many new KeyValue pairs as required via this.context#forward()
context.schedule(1000, PunctuationType.WALL_CLOCK_TIME, new Punctuator(..));
}
KeyValue transform(K key, V value) {
// can access this.state
// can emit as many new KeyValue pairs as required via this.context#forward()
return new KeyValue(key, value); // can emit a single value via return -- can also be null
}
void close() {
// can access this.state
// can emit as many new KeyValue pairs as required via this.context#forward()
}
}
}
}
만약에 transform한 결과의 KStream에 aggregation 혹은 join을 하는 경우에 data redistribution이 발생할 수 있다.