KafkaStream Architecture
by Gunju Ko
Architecture
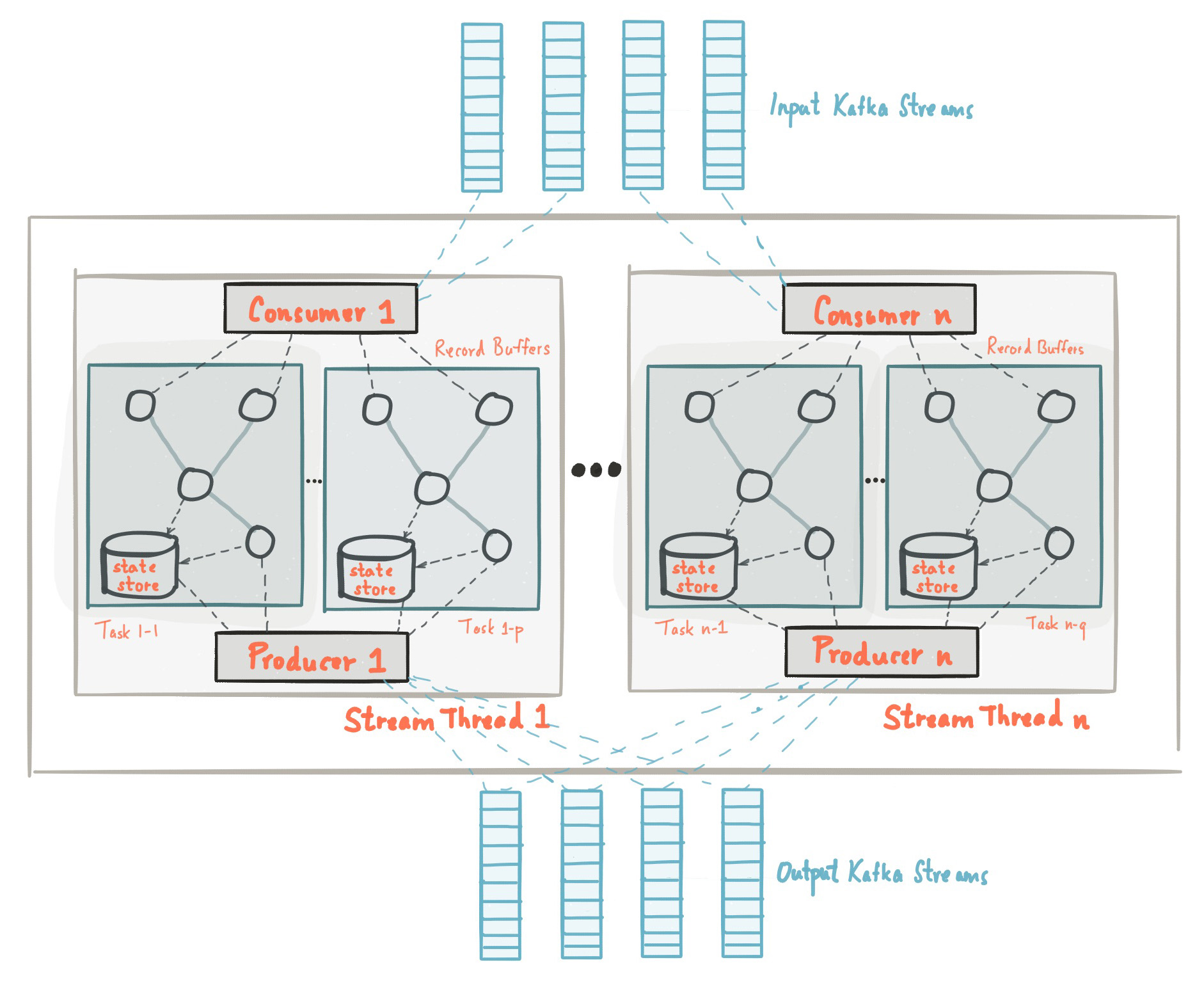
이 글에서는 Kafka Stream의 Thread Modeling과 Task에 대해서 정리한 글이다. 더 자세한 내용은 공식문서를 참고하길 바란다. Kafka Stream을 사용하면 스트림 어플리케이션을 쉽게 개발할 수 있다. 하지만 이를 위해서는 기본적으로 Kafka Streams가 어떻게 Thread를 생성하고 각 Thread에 Task를 할당하는지 알 필요가 있다. 아래의 그림은 Kafka Streams을 사용한 어플리케이션의 구조를 나타낸다. 아래의 그림은 여러 개의 Task를 포함하고 있는 여러 개의 StreamThread를 포함하는 Kafka Streams 어플리케이션을 나타낸다.
Processor Topology
프로세서 토폴로지는 어플리케이션의 스트림 프로세싱 로직을 정의한다. 즉 input 데이터를 output 데이터로 어떻게 변환할 것인가를 토폴로지를 통해서 정의한다. 토폴로지는 스트림으로 연결된 스트림 프로세서(노드)의 그래프이다.
- Source Processor : 특별한 타입의 스트림 프로세서로 업스트림 프로세스를 가지고 있지 않다. Source Processor는 하나 이상의 토픽에서 레코드를 읽어와서 토폴로지에 대한 Input 스트림을 생성하고 다운 스트림 프로세서로 전달한다.
- Sink Processor : 특별한 타입의 스트림 프로세서로 다운스트림 프로세서를 가지고 있지 않다. Sink Processor는 업스트림 프로세서로부터 전달받은 Record를 명시된 카프카 토픽으로 보낸다.
스트림 프로세싱 어플리케이션에서는 하나 이상의 토폴로지를 정의한다. (보통은 하나를 정의한다) 개발자는 low-level Processor API 혹은 Kafka Streams DSL를 통해서 토폴로지를 정의할 수 있다.

프로세서 토폴로지는 스트림 처리 코드에 대한 논리적인 추상화일 뿐이다. 런타임시 논리적인 토폴로지는 인스턴스화되며 병렬 처리를 위해서 어플리케이션 내에서 복제된다.
Stream Partition and Tasks
카프카는 데이터를 분할해서 저장하고 있다. 그리고 Kafka Streams는 데이터를 처리하기 위해서 데이터를 분할한다. 이러한 분할은 데이터 locality, elasticity, scalability, high performance, 그리로 fault tolerance를 가능하게 한다. Kafka Stream은 카프카 토픽 파티션 기반의 병렬 처리 모델의 논리 단위로 stream partitions와 stream tasks 개념을 사용한다. 병렬성이라는 맥락에서 Kafka Streams와 Kafka는 깊은 관련이 있다.
- 각각의 Stream partition은 하나의 토픽 파티션에 매핑되는 정렬된 data record의 연속이다.
- Stream 안에 있는 하나의 data record는 카프카 토픽에 있는 하나의 메시지와 매핑된다.
- record가 어떤 partition으로 들어갈지는 record의 key로 결정한다.
Kafka Streams는 어플리케이션의 Source 토픽의 파티션을 기반으로해서 고정된 수의 Task를 생성한다. 그리고 각각의 Task에 Source 토픽의 파티션들을 할당한다. Task에 할당된 파티션은 절대로 변하지 않는다. 따라서 각각의 Task는 어플리케이션의 고정된 병렬 처리의 단위가 된다. Task는 할당된 파티션을 기반으로 자신의 프로세서 토폴로지를 인스턴스화 할 수 있다. 또한 Task는 할당된 각 파티션에 대한 레코드 버퍼를 가지고 있다. 그리고 레코드 버퍼에서 한번에 하나씩 꺼내서 처리한다. 결과적으로 Task를 독립적이고 병렬적으로 처리할 수 있다.
어플리케이션이 생성할 수 있는 최대 StreamThread의 개수는 Task의 수에 제한된다. 그리고 Task의 수는 Source 토픽 중에서 가장 많은 파티션을 가진 토픽의 파티션 수이다. 예를 들어 Source 토픽의 파티션의 개수가 5개라면, Task는 총 5개가 생성되며 결과적으로 최대 StreamThread를 5개까지 만들 수 있다. 6개도 가능하지만 그렇게 된다면 1개의 StreamThread는 Task를 할당받지 못하지 때문에 하나의 StreamThread는 놀고 있게 된다. 하지만 만약에 6개의 StreamThread 중에서 Task를 할당받은 StreamThread중 하나가 종료된다면 종료된 StreamThread가 할당받았던 Task를 놀고 있던 StreamThread에게 할당한다.
아래의 그림은 각각의 토픽(Topic A, Topic B)으로 부터 하나의 파티션을 할당받은 Task이다.
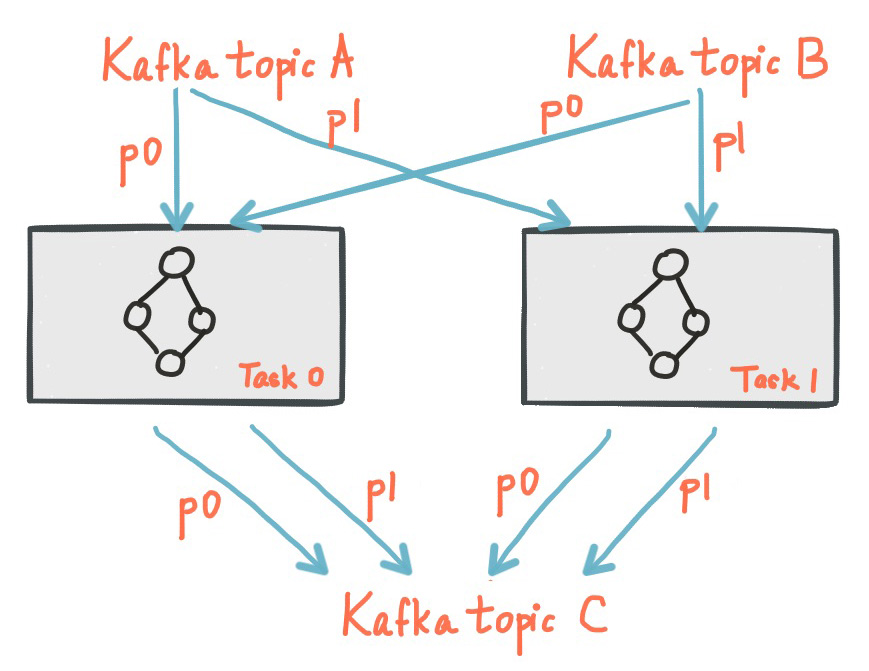
여러 개의 어플리케이션이 동일한 컴퓨터에서 실행될 수 있으며 혹은 여러대의 컴퓨터에서 실행될 수 있다. 그러면 Task들은 라이브러리에 의해서 실행 중인 어플리케이션으로 자동으로 분배된다. Task에 할당된 파티션은 절대 변하지 않는다. 만약 어플리케이션이 중단되면, 어플리케이션에 할당된 Task들은 자동으로 다른 인스턴스에서 재시작될 것이며 같은 파티션을 계속해서 읽어올 것이다.
Thread Modeling
Kafka Stream에서는 하나의 어플리케이션에서 여러개의 스레드를 생성하여, Record 처리를 병렬적으로 수행할 수 있다. 각각의 스레드는 프로세서 토폴로지가 있는 하나 이상의 Task들을 독립적으로 실행한다. 예를 들어, 아래의 그림은 2개의 Stream Task를 실행하는 하나의 Stream Thread를 나타낸다.
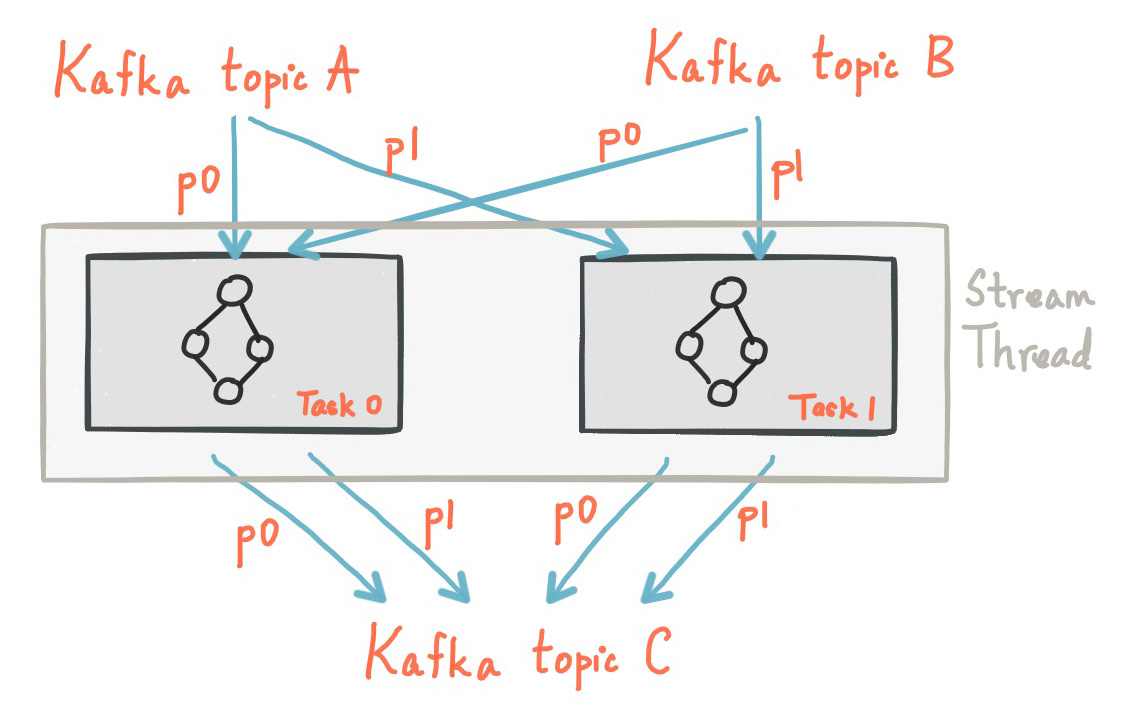
더 많은 StreamThread를 생성하거나 혹은 더 많은 어플리케이션 인스턴스를 시작하는 것은 단지 토폴로지를 복제하는 것이다. 그리고 각 토폴로지가 서로 다른 카프카 파티션을 처리하도록 함으로써 효과적으로 병렬 처리한다. 각각의 스레드들은 서로의 상태를 공유할 필요가 없다. 따라서 스레드간의 조정은 필요하지 않다. 따라서 토폴로지를 여러 개의 스레드에서 병렬적으로 실행시키는 것은 쉽다. 여러 개의 StreamThread 간의 Partition 할당은 Kafka’s server-side coordination 기능을 사용하여 Kafka Stream에 의해서 투명하게 처리된다.
앞서 말했듯이, Kafka Stream를 사용하는 어플리케이션을 확장하는 것은 매우 쉽다. 단지 어플리케이션을 추가로 실행시켜주기만 하면 된다. StreamThread는 Source 토픽의 최대 파티션 개수만큼 생성할 수 있다. 따라서 각각의 Stream Thread는 적어도 하나의 파티션을 할당 받는다.
Example
카프카 스트림이 제공하는 병렬 처리 모델을 이해하기 위해 예제를 살펴보겠다. Kafka Streams 어플리케이션이 파티션의 개수가 3인 A, B 토픽을 읽고있다고 가정하자. 이제 스레드 수가 2로 설정된 어플리케이션을 실행시킨다. 그러면 어플리케이션의 instance1-thread1, instance1-thread2 이렇게 2개의 스레드를 생성한다. Kafka Streams는 총 3개의 Task를 생성한다. 왜나하면 Source 토픽 중에서 가장 많은 파티션의 개수를 가진 토픽의 파티션 수가 3이기 때문이다. 그리고 총 6개의 파티션을 3개의 Task에 고르게 할당한다. 따라서 각 Task는 A, B 토픽의 파티션을 각각 하나씩 할당 받는다. 마지막으로 3개의 Task를 2개의 StreamThread에게 가능한 고르게 분배한다. 이 예제에서는 첫번째 StreamThread가 2개의 Task를 실행한다. 그리고 나머지 StreamThread는 하나의 Task를 실행한다.

이제 새로운 어플리케이션을 실행했다고 가정해보자. 새로운 어플리케이션은 하나의 StreamThread를 생성하도록 설정하고 다른 서버에서 실행시킨다. 새로운 StreamThread인 instance2-thread1가 생성될 것이며, Task들은 아래와 같이 다시 할당될 것이다.

재할당이 일어나면 Task와 관련된 로컬 State Store등이 기존 StreamThread에서 새롭게 할당된 StreamThread로 마이그레이션 된다.
State
Kafka Streams는 State Store를 제공한다. State Store는 데이터를 저장하고 쿼리하는데 사용할 수 있다. 이는 Stateful 오퍼레이션을 구현할 때 중요한 기능이다. 예를 들면 Kafka Stream DSL은 join() 또는 aggregate()와 같은 stateful 오퍼레이션이 호출되면 State Store을 자동으로 생성하고 관리한다.
Kafka Streams 어플리케이션의 모든 Stream Task는 하나 이상의 로컬 State Store를 포함할 수 있다. 그리고 API를 통해서 State Store에 처리에 필요한 데이터를 저장하고 쿼리 할 수 있다. State Store는 RocksDB 데이터베이스 혹은 인메모리 해쉬 맵, 혹은 다른 자료구조일 수 있다. Kafka Streams는 로컬 State Store에 대해 fault-tolerance와 자동 복구 기능을 제공한다.
아래의 그림은 로컬 State Store를 가지고 있는 2개의 Stream Task를 보여준다.
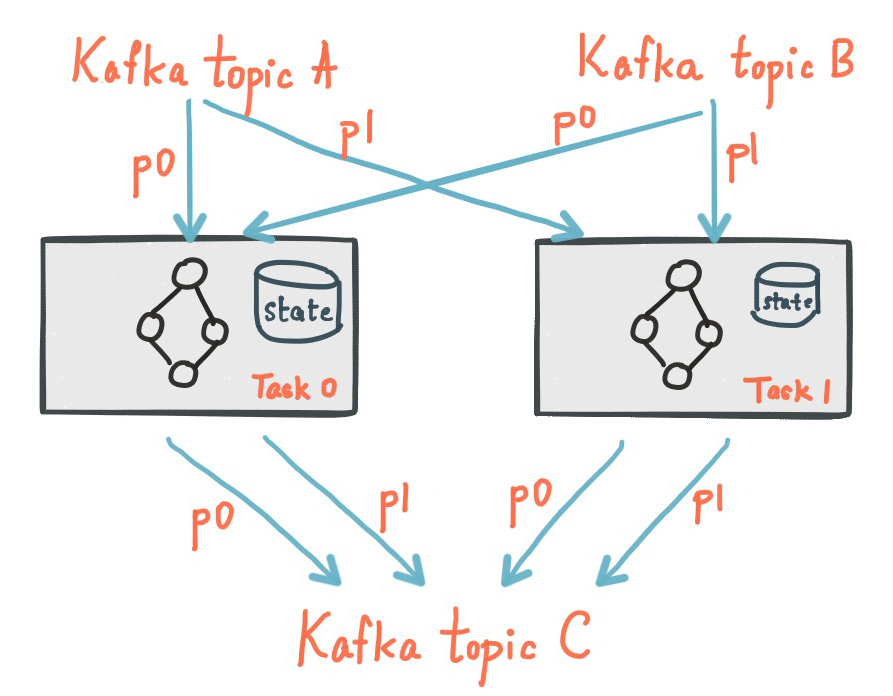
하나의 Kafka Streams 어플리케이션는 보통 여러 개의 어플리케이션을 실행한다. 그러면 어플리케이션의 전체 상태는 각 어플리케이션의 로컬 State Store로 퍼지게된다. Kafka Streams API는 사용해서 로컬에 있는 State Store를 사용할 수 있으며, 전체 어플리케이션의 State Store를 사용할 수도 있다. 전체 State Store를 조회하는 것은 Interactive Queries를 참고해라
Memory management
Kafka Streams에서 토폴로지에서 사용하는 총 RAM 사이즈를 명시할 수 있다. 그리고 State Store에 쓰기 작업을 하거나 다른 노드로 다운스트림으로 전달하기 전에 내부 캐싱 및 압축을 하는데 사용된다. 캐시는 DSL, Processor API의 구현이 약간 다르다. 설정된 캐시 사이즈는 StreamThread에게 동일하게 나누어진다. 그리고 각각의 StreamThread는 메모리 풀을 관리하며 Task의 프로세서 노드는 캐싱을 위해서 메모리 풀을 사용한다. 특히 캐시는 State Store를 가지고 있는 Stateful 프로세서 노드가 사용한다. 캐싱 기능을 사용한다는 것은 StateStore의 구현체 중에서 CachedStateStore 인터페이스를 구현한 StateStore를 사용한다는 것을 의미한다. 대표적으로 CachingKeyValueStore가 있다.

캐시는 3가지 기능을 가지고 있다.
- State Store에서 데이터를 조회하는 속도를 높이기 위해서 Read cache의 기능을 한다.
- State Store의 write-back 버퍼 역할을 한다. write-back 캐시는 Record를 하나씩 State Store에 저장하는게 아니라, 배치로 여러개의 Record를 한번에 저장하는 것을 가능하게 해준다. 또한 같은 Key를 가진 Record는 캐시에서 압축되기 때문에 State Store(그리고 changelog 토픽)로 전송되는 Request의 수를 줄여준다.
- write-back 캐시는 다운스트림 프로세서 노드에게 전달되는 Record의 수를 줄여준다. 캐시 기능을 사용하지 않은 경우 Processor에서 처리된 결과는 바로 다운 스트림 프로세서로 전달된다. 하지만 캐싱 기능을 사용하면, Processor에서 처리된 결과가 바로 다운 스트림 프로세서로 전달되지 않고, 캐시를 Flush할 때 Flush된 데이터들을 차례로 다운 스트림으로 전달한다.
이러한 캐시기능은 다음과 같은 트레이드 오프 결정을 할 수 있게 해준다.
- 캐시 사이즈를 작게 하는 경우 : 짧은 간격으로 다운스트림으로 레코드를 전달한다.
- 캐시 사이즈를 크게 하는 경우 : 긴 간격으로 다운스트림으로 레코드를 전달한다. 일반적으로 이는 Kafka의 네트워크 IO를 줄이고 RocksDB State Store를 사용하는 경우 로컬 Disk IO를 줄여준다.
최종적인 결과는 캐시 사이즈와 상관없이 동일하다. 따라서 캐시 기능은 안전한다. 캐시에 있는 데이터가 언제 어떻게 압축이 될지 예측하는 것은 불가능하다. 왜냐하면 이는 많은 요소들에 영향을 받기 때문이다. 아래와 같은 요소들이 영향을 미친다.
- Cache Size
- 처리중인 데이터의 특징
- commit.interval.ms 설정 값
더 자세한 내용은 Memory Management를 참고해라
More Info about CachedStateStore
위에서 캐싱 기능을 사용하는 경우에 Processor의 처리 결과가 바로 다운 스트림으로 전달되지 않고, 캐시를 Flush할 때 Flush된 데이터를 다운 스트림으로 전달한다고 했는데 해당 부분은 코드를 보지 않으면 바로 이해가 되지 않는다. 이 부분은 코드를 보면 좀 더 명확해진다.
아래의 코드는 KStreamAggregator의 process 메소드이다. 아래의 결과를 보면 Record를 처리 한 뒤에 그 결과를 StateStore에 저장하고 마지막에 TupleForwarder#maybeForward(key, newAgg, oldAgg) 메소드를 호출한다.
@Override
public void process(K key, V value) {
// If the key or value is null we don't need to proceed
if (key == null || value == null) {
return;
}
T oldAgg = store.get(key);
if (oldAgg == null) {
oldAgg = initializer.apply();
}
T newAgg = oldAgg;
// try to add the new value
newAgg = aggregator.apply(key, value, newAgg);
// update the store with the new value
store.put(key, newAgg);
tupleForwarder.maybeForward(key, newAgg, oldAgg);
}
아래의 코드는 TupleForwarder#maybeForward 메소드이다. 만약에 cachedStateStore가 널인 경우에 ProcessorContext#forward 메소드를 통해서 처리 결과를 다운스트림으로 보낸다. 하지만 널이 아닌 경우에는 처리 결과가 다운스트림으로 전달되지 않는다. 캐싱 기능을 사용할 때는 cachedStateStore가 널이 아니다. (StateStore가 CachedStateStore 인터페이스를 구현하고 있는 경우) 따라서 이 경우에는 처리 결과가 다운스트림으로 전달되지 않는다.
public void maybeForward(final K key,
final V newValue,
final V oldValue) {
if (cachedStateStore == null) {
if (sendOldValues) {
context.forward(key, new Change<>(newValue, oldValue));
} else {
context.forward(key, new Change<>(newValue, null));
}
}
}
그러면 Processor의 처리 결과가 언제 다운스트림으로 전달될까? 이는 CachedStateStore의 구현체마다 다를수 있는데, CachingKeyValueStore에 대해서만 살펴보도록 하겠다. CachingKeyValueStore의 put() 메소드에서는 putInternal 메소드를 호출한다. 아래의 코드는 CachingKeyValueStore의 put 메소드이다.
// CachingKeyValueStore#put
@Override
public void put(final Bytes key, final byte[] value) {
Objects.requireNonNull(key, "key cannot be null");
validateStoreOpen();
lock.writeLock().lock();
try {
// for null bytes, we still put it into cache indicating tombstones
putInternal(key, value);
} finally {
lock.writeLock().unlock();
}
}
private void putInternal(final Bytes key, final byte[] value) {
cache.put(cacheName, key, new LRUCacheEntry(value, true, context.offset(),
context.timestamp(), context.partition(), context.topic()));
}
CachingKeyValueStore의 put 메소드에서는 ThreadCache.put 메소드를 호출한다. 아래의 코드는 ThreadCache.put 메소드이다.
// ThreadCache#put
public void put(final String namespace, Bytes key, LRUCacheEntry value) {
numPuts++;
final NamedCache cache = getOrCreateCache(namespace);
cache.put(key, value);
maybeEvict(namespace);
}
getOrCreateCache는 cacheName에 해당하는 NamedCache를 리턴한다. 만약에 cacheName에 해당하는 NamedCache가 존재하지 않으면 NamedCache를 생성한다. 그리고 NamedCache#put 메소드를 호출해서 캐시에 key와 value를 저장한다. 마지막에 maybeEvict 부분이 중요하다. 아래의 코드를 보면서 설명하도록 하겠다.
// ThreadCache#maybeEvict
private void maybeEvict(final String namespace) {
int numEvicted = 0;
while (sizeBytes() > maxCacheSizeBytes) {
final NamedCache cache = getOrCreateCache(namespace);
// we abort here as the put on this cache may have triggered
// a put on another cache. So even though the sizeInBytes() is
// still > maxCacheSizeBytes there is nothing to evict from this
// namespaced cache.
if (cache.size() == 0) {
return;
}
cache.evict();
numEvicts++;
numEvicted++;
}
if (log.isTraceEnabled()) {
log.trace("Evicted {} entries from cache {}", numEvicted, namespace);
}
}
만약 현재 ThreadCache의 크기가 maxCacheSizeBytes보다 큰 경우에는 cacheName에 해당하는 NamedCache.evict() 메소드를 호출한다. 이는 ThreadCache의 크기가 maxCacheSizeBytes 보다 작거나 NamedCache의 크기가 0이 될 때까지 계속된다.
아래의 코드는 NamedCache#evict 메소드의 코드이다. 가장 오래된 LRUNode를 캐시에서 삭제하고, 만약에 LRUNode의 LRUCacheEntry가 dirty인 경우에는 NamedCache#flush 메소드가 호출된다. CachingKeyValueStore는 LRUCacheEntry를 생성할 때 항상 dirty를 true로 생성하기 때문에, 항상 flush 메소드가 호출된다.
// NamedCache#evict
synchronized void evict() {
if (tail == null) {
return;
}
final LRUNode eldest = tail;
currentSizeBytes -= eldest.size();
remove(eldest);
cache.remove(eldest.key);
if (eldest.entry.isDirty()) {
flush(eldest);
}
}
private void flush(final LRUNode evicted) {
numFlushes++;
// 생략
if (dirtyKeys.isEmpty()) {
return;
}
final List<ThreadCache.DirtyEntry> entries = new ArrayList<>();
final List<Bytes> deleted = new ArrayList<>();
// evicted already been removed from the cache so add it to the list of
// flushed entries and remove from dirtyKeys.
if (evicted != null) {
entries.add(new ThreadCache.DirtyEntry(evicted.key, evicted.entry.value, evicted.entry));
dirtyKeys.remove(evicted.key);
}
for (Bytes key : dirtyKeys) {
final LRUNode node = getInternal(key);
if (node == null) {
throw new IllegalStateException("Key = " + key + " found in dirty key set, but entry is null");
}
entries.add(new ThreadCache.DirtyEntry(key, node.entry.value, node.entry));
node.entry.markClean();
if (node.entry.value == null) {
deleted.add(node.key);
}
}
// clear dirtyKeys before the listener is applied as it may be re-entrant.
dirtyKeys.clear();
listener.apply(entries);
for (Bytes key : deleted) {
delete(key);
}
}
flush 코드를 차례로 분석하면 아래와 같다.
- 파리미터로 넘어온 LRUNode evicted를 flush entries(List
entries)에 추가한다. 그리고 evicted는 이미 캐시에서 제거된 상태이기 때문에 dirtyKeys에서 제거한다. - dirtyKeys를 모두 순회하면서, dirty한 LRUNode를 flush entries에 추가한다. 그리고 List<
Bytes> deleted에도 추가한다. - dirtyKeys.clear() 메소드를 호출한다.
- DirtyEntryFlushListener#apply 메소드를 호출하며 인자로 entries를 전달한다. entries는 evicted + 캐시에 존재했던 모든 dirtry entry이다.
- 마지막으로 캐시에 존재했던 모든 dirtry LRUNode를 삭제한다.
결과적으로 flush를 호출하면 모든 dirtry LRUNode들이 삭제된다. 또한 삭제된 모든 Ditry Entry를 DirtyEntryFlushListener#apply 메소드의 인자로 전달한다. 아래의 코드는 CachingKeyValueStore의 DirtyEntryFlushListener 인터페이스 구현체이다. 코드를 보면 모든 DitryEntry에 대해서 putAndMaybeForward 메소드를 호출한다.
// CachingKeyValueStore
new ThreadCache.DirtyEntryFlushListener() {
@Override
public void apply(final List<ThreadCache.DirtyEntry> entries) {
for (ThreadCache.DirtyEntry entry : entries) {
putAndMaybeForward(entry, (InternalProcessorContext) context);
}
}
}
// CachingKeyValueStore#putAndMaybeForward
private void putAndMaybeForward(final ThreadCache.DirtyEntry entry, final InternalProcessorContext context) {
final RecordContext current = context.recordContext();
try {
context.setRecordContext(entry.recordContext());
if (flushListener != null) {
V oldValue = null;
if (sendOldValues) {
final byte[] oldBytesValue = underlying.get(entry.key());
oldValue = oldBytesValue == null ? null : serdes.valueFrom(oldBytesValue);
}
// we rely on underlying store to handle null new value bytes as deletes
underlying.put(entry.key(), entry.newValue());
flushListener.apply(serdes.keyFrom(entry.key().get()),
serdes.valueFrom(entry.newValue()),
oldValue);
} else {
underlying.put(entry.key(), entry.newValue());
}
} finally {
context.setRecordContext(current);
}
}
putAndMaybeForward는 다음과 같은 순서로 진행된다.
- InternalProcessorContext#setRecordContext 메소드를 호출해서 ProcesContext의 RecordContext를 DirtyEntry에 존재하는 RecordContext로 set한다.
- 만약에 flushListener가 널인 경우에 underlying.put(entry.key(), entry.newValue()) 메소드를 호출한다. underlying 멤버 변수의 타입은 KeyValueStore로 KeyValueStore.put 메소드를 호출함으로써 캐싱되었던 값을 실제 StateStore에 반영한다.
- 만약에 flushListener가 널이 아닌 경우 underlying.put 메소드를 호출해서 캐싱되었던 값을 실제 StateStore에 반영한다. 그리고 CacheFlushListener#apply(final K key, final V newValue, final V oldValue) 메소드를 호출한다. 이 때 oldValue는 이전에 StateStore에 존재했던 값이고 newValue는 캐싱되었던 값이다.(방금 StateStore에 반영된 값이다) 보통 CachingKeyValueStore는 flushListener 멤버 변수를 ForwardingCacheFlushListener 타입의 객체로 세팅한다. 따라서 ForwardingCacheFlushListener#apply 메소드가 호출이 된다
ForwardingCacheFlushListener#apply의 코드는 아래와 같다. 간단하게 설명하면 InternalProcessorContext#forward 메소드를 통해서 데이터를 다운 스트림으로 전달한다.
// ForwardingCacheFlushListener#apply
@Override
public void apply(final K key, final V newValue, final V oldValue) {
final ProcessorNode prev = context.currentNode();
context.setCurrentNode(myNode);
try {
if (sendOldValues) {
context.forward(key, new Change<>(newValue, oldValue));
} else {
context.forward(key, new Change<>(newValue, null));
}
} finally {
context.setCurrentNode(prev);
}
}
굉장히 복잡한 과정을 거치지만 간단하게 정리하면 아래와 같다.
- Processor가 CachedStateStore 인터페이스를 구현한 StateStore를 사용하는 경우 처리된 결과가 다운 스트림으로 바로 전달되지 않는다. 처리된 결과가 캐시에만 저장되며 나중에 캐시가 flush 될 때 캐시되었던 데이터들이 차례로 다운 스트림으로 전달된다.
- CachedStateStore.put 메소드는 실제로 캐시에만 데이터를 저장하며, changelog 토픽이나 실제 StateStore(Rock DB등)에 바로 반영되지 않는다.
- CachedStateStore.put 호출시 캐싱된 데이터가 maxCacheSizeBytes보다 큰 경우에는 캐싱된 데이터를 전부 flush 한다.
- 캐싱된 데이터가 flush되면서 이를 실제 StateStore, changelog 토픽에 반영된다. 그리고 이 때 캐싱 되었었던 데이터들이 다운 스트림으로 차례대로 전달되어 하나씩 처리된다.
commit.interval.ms
그러면 캐시에 있는 데이터는 캐시가 가득찬 경우에만 flush 될까? 결과적으로 말하면 아니다. 캐시가 flush 되는데 영향을 미치는 요소는 여러가지가 있다. 가장 대표적으로는 commit.interval.ms 설정값이다. 보통 commit.interval.ms 기간을 주기로 commit을 한다. 그리고 commit을 할 때, State Store도 flush 시킨다. 따라서 commit.interval.ms 기간이 짧은 경우에는 캐시가 자주 flush 될 수 있다.
Fault Tolerance
Task는 Kafka Consumer의 fault-tolerant 기능을 활용하여 오류를 처리한다. 만약에 Task를 실행하는 어플리케이션에 오류가 생긴 경우에 Kafka Streams는 자동으로 해당 Task를 다른 어플리케이션에서 재시작한다. 게다가 Kafka Streams는 로컬 State Store가 fault-tolerant하게 한다. 이는 State Store에 대한 복제된 changelog topic을 유지함으로써 가능하게 된다. changelog 토픽은 파티셔닝 되어 있으며, 각각의 로컬 State Store는 전용 changelog 토픽 파티션을 가지고 있다. 또한 changelog 토픽은 LogCompaction 기능을 사용한다. 그래서 기존 데이터를 안전하게 제거하여 토픽이 무한정 증가하지 않도록 한다. 만약에 어플리케이션이 종료되어 Task들이 다른 어플리케이션에서 재시작하는 경우 Kafka Streams는 Task와 관련된 State Store를 이전 상태로 복구하는데 이 때 changelog 토픽을 사용해서 State Store를 복구한다. Kafka Streams는 새로 할당된 Task를 재시작하기 전에 changelog 토픽을 다시 읽어드려서 State Store를 복구한다.
최적화 : Task를 초기화의 비용은 보통 Changelog 토픽을 읽어서 State Store를 복구하는데 걸리는 시간에 많은 영향을 받는다. 복구 시간을 최소화하기 위해서, 로컬 State의 standby replicas를 가지도록 어플리케이션을 설정할 수 있다. 만약에 Task가 다른 어플리케이션으로 이동해야 하는 경우 Kafka Streams는 해당 Task의 standby replicas를 가지고 있는 어플리케이션에게 Task를 할당하려고 시도한다. 이러한 방법으로 복구 시간을 최소화하려고 한다. Standby replicas의 수는 num.standby.replicas 속성을 통해서 설정할 수 있다. 더 자세한 내용은 Optional configuration parameters를 참고해라
Backpressure
Kafka Streams는 백프레셔 기능이 필요없다. 왜냐하면 depth-first 처리 전략을 사용하기 때문이다. 하나의 Record는 처리를 위해서 전체 프로세서 토폴로지를 거친다. 그리고 그 다음 Record가 차례로 처리된다. 즉 하나의 Topology는 한번에 하나의 Record만 처리한다. 결과적으로 연결된 두 개의 스트림 프로세서 사이에서 버퍼링된 Record는 존재하지 않는다. 또한 카프카 스트림은 내부적으로 Kafka Consumer를 사용한다. Kafka Consumer는 pull-based 기반이므로 다운스트림 프로세서가 Record를 읽어들이는 속도를 조절할 수 있도록 해준다.
서로 독립적으로 처리되는 서브 토폴로지를 가지고 있는 프로세서 토폴로지의 경우에도 동일하게 적용된다. 예를 들어 아래의 코드는 두개의 독립적인 서브 토폴로지를 정의하는 한다.
stream1.to("my-topic");
stream2 = builder.stream("my-topic");
서브 토폴로지간의 데이터의 교환은 카프카를 통해서만 이루어진다. 즉 서브 토폴로지간에 데이터를 직접적으로 교환하는 경우는 없다. 위의 예제의 경우 “my-topic” 토픽을 통해서 데이터가 교환된다. 따라서 이와 같은 상황에서도 백프레셔는 필요하지 않다.
출처
- https://kafka.apache.org/11/documentation/streams/architecture
- https://docs.confluent.io/current/streams/architecture.html