카프카 SQL을 이용한 스트리밍 처리
by Gunju Ko
이 글은 “카프카, 데이터 플랫폼의 최강자” 책 내용을 정리한 글입니다.
카프카 SQL을 이용한 스트리밍 처리
1. KSQL의 등장 배경
- 카프카를 데이터 버스로 사용하고, 여기에 있는 데이터를 가공해서 다시 다른 스토리지나 데이터베이스에 저장하는 경우가 많아짐
- 람다 아키텍처
- raw 데이터를 처리해서 기간과 용량에 따라 별도의 저장소를 가져가는 것을 람다 아키텍처라고 한다.
- 람다 아키텍처는 파이프라인을 통해 단기 데이터와 장기 데이터를 관리할 수 있다.
- 데이터 조회 영역에서는 큰 어려움 없이 단기/장기 데이터를 한번에 조회할 수 있다.

람다 아키텍처
- https://bcho.tistory.com/984
- 람다 아키테처의 단점
- 파이프라인을 구성하는데 많이 기술이 들어가기 때문에 부담이 될 수 있다.
- 단기 데이터와 장기 데이터를 별도로 관리해야 하기 때문에 관리 비용 측면에서 부담이 된다.
- 카파 아키텍처 등장
- 위에서 말한 람다 아키텍처의 한계로 인해 등장함
- 간단한 계산과 필터링은 카프카에서 직접 수행하고, 계산 프로그램 역시도 장기와 단기 구분없이 동일한 프로그램을 사용
- 이 때 사용하는 기술 중 하나가 KSQL이다.
2. KSQL과 카파 아키텍처
- 카파 아키텍처
- 데이터의 크기나 기간에 관계없이 하나의 계산 프로그램을 사용하는 방식
- 장기 데이터를 빨리 조회할 수 있도록 배치 작업을 써서 장기 데이터를 따로 저장하는것이 아니라 장기 데이터 조회가 필요할 경우에 계산해서 결과를 그 때 그 때 전달하는 것이다.
- 필요한 데이터를 가져오는 부분을 “조회” 대신 “계산”으로 전환함으로써 데이터 파이프라인뿐만 아니라 데이터 저장소 관리를 단순화 한다.
- 데이터를 가져오는 영역을 단순하게 해주는것이 KSQL이다.
3. KSQL 아키텍처
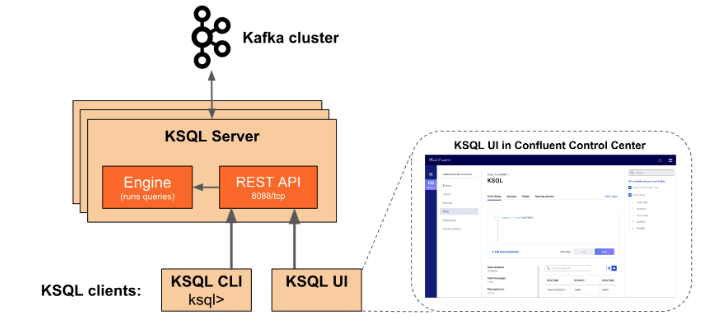
- KSQL 서버
- 사용자로부터 쿼리를 받을 수 있는 REST API 서버와 넘겨 받은 쿼리를 직접 실행하는 KSQL 엔진 클래스로 구성된다.
- KSQL 엔진은 사용자의 쿼리를 논리적/물리적 실행 계획으로 변환하고, 지정된 카프카 클러스터의 토픽으로부터 데이터를 읽거나 토픽을 생성해 데이터를 생성하는 역할을 한다.
- 논리 계획과 물리 계획을 작성할 때 필요한 테이블 메타 정보는 별도의 저장소에 저장하는 것이 아니라 KSQL 서버의 메모리에 있다. 그리고 필요한 경우 command라는 카프카 토픽에 저장한다.
- command 토픽에는 KSQL 서버 생성 후에 실행한 테이블 관련 명령어가 들어 있기 때문에 KSQL 인스턴스나 서버가 추가되었을 때 메타 데이터를 클러스터 간에 복제하는 것이 아니라 이 토픽을 읽어서 자신의 메모리에 생성한다.
- KSQL 클라이언트
- KSQL에 연결하고 사용자가 SQL 쿼리문을 작성할 수 있게 한다.
- 단순한 쿼리문을 통해 카프카 데이터에 접근할 수 있다.
- 스트림 : 데이터가 계속 기록될 수 있지만, 한번 기록된 이벤트는 변경될 수 없다.
- 테이블 : 이벤트에 따른 현재 상태를 나타낸다. 스트림과 달리 변경이 가능하다.
스트림 생성
CREATE STREAM 스트림이름({ 컬러이름 컬럼_데이터타입 } [,...]) WITH (프로퍼티_이름 = 프로퍼티값 [,...]);
- 컬럼 데이터 타입
- BOOLEAN
- INTEGER
- BIGINT
- DOUBLE
- VARCHAR (or STRING)
- JSON
- 프로퍼티 값
- KAFKA_TOPIC : 이 스트림에서 사용할 토픽의 이름. 토픽은 반드시 미리 생성되어 있어야 한다.
- VALUE_FORMAT : Serialization/Deserialization시 사용할 데이터 포맷
- KEY : 카프카 토픽 메시지 키와 KSQL 스트림의 컬럼을 연결한다.
- TIMESTAMP : 카프카 토픽의 시간값을 KSQL의 컬럼과 연결한다.
CREATE OR REPLACE stream PRODUCT_CHANGED with(KAFKA_TOPIC='PRODUCT_CHANGED', VALUE_FORMAT='AVRO');
- 스트림 이름은 PRODUCT_CHANGED이고 이 스트림이 사용할 토픽은 PRODUCT_CHANGED이며, 데이터 포맷은 AVRO이다.
쿼리 결과로 스트림 생성
- Select 쿼리의 결과를 특정 카프카에 지속적으로 입력하도록
AS SELECT를 사용해 쿼리 결과에서 스트림을 생성할 수 있다. CREATE STREAM또는CREATE TABLE을 붙이면 쿼리가 영구적으로 실행된다. 그리고 이렇게 쿼리로 생성된 테이블이나 스트림은 동일한 이름(혹은 KAKFA_TOPIC 프로퍼티값)의 카프카 토픽에 그 결과를 저장한다.PARTITION BY를 적용할 경우 해당 컬럼 이름을 토픽의 키로 사용한다.
create stream KSQL_REQUEST_MATCH_CATEGORY
WITH (KAFKA_TOPIC='KSQL_REQUEST_MATCH_CATEGORY', PARTITIONS=10, REPLICAS=3) as
select
nv_mid,
rcv_match_cat_id ,
mall_seq,
workr_id
from PRODUCT_CHANGED
where
rcv_match_cat_id is not null
AND nv_mid is not null
AND mall_seq is not null
AND workr_id is not null
AND rcv_rcmd_match_nv_mid is null;
- PARTITIONS : 토픽 생성시 사용할 파티션 개수. 설정하지 않을 경우 인풋 스트림이나 테이블의 리플리케이션 팩터를 그대로 사용한다.
- REPLICAS : 토픽 생성시 사용할 리플리케이션 팩터. 설정하지 않을 경우 인풋 스트림이나 테이블의 리플리케이션 팩터를 그대로 사용한다.
테이블 생성
CREATE TABLE 테이블_이름({ 컬러이름 컬럼_데이터타입 } [,...]) WITH (프로퍼티_이름 = 프로퍼티값 [,...]);
예제
CREATE TABLE user( usertimestamp BIGINT, user_id VARCHAR, gender VARCHAR, region_id VARCHAR)
WITH (VALUE_FORMAT = 'JSON', KAFKA_TOPIC='my-user-topic');
- DESCRIBE 명령어를 사용하면 생성된 스트림/테이블 정보를 확인할 수 있다.
DESCRIBE user;