Standby Task
by Gunju Ko
Standby Task
Standby Task란
KafkaStreams는 State Store를 제공한다. 스트림 프로세싱 어플리케이션에서는 데이터를 저장하고 조회하기 위해서 State Store를 사용한다. 이는 Stateful Operation을 구현하기 위해 꼭 필요한 기능이다. KafkaStreams 내의 모든 Task들은 하나 이상의 State Store를 가질 수 있다. State Store에 데이터를 저장하거나 조회하기 위해 API를 통해 접근할 수 있다. State Store의 구현체로는 Rocks DB, In Memory 해쉬 맵 등이 있다.
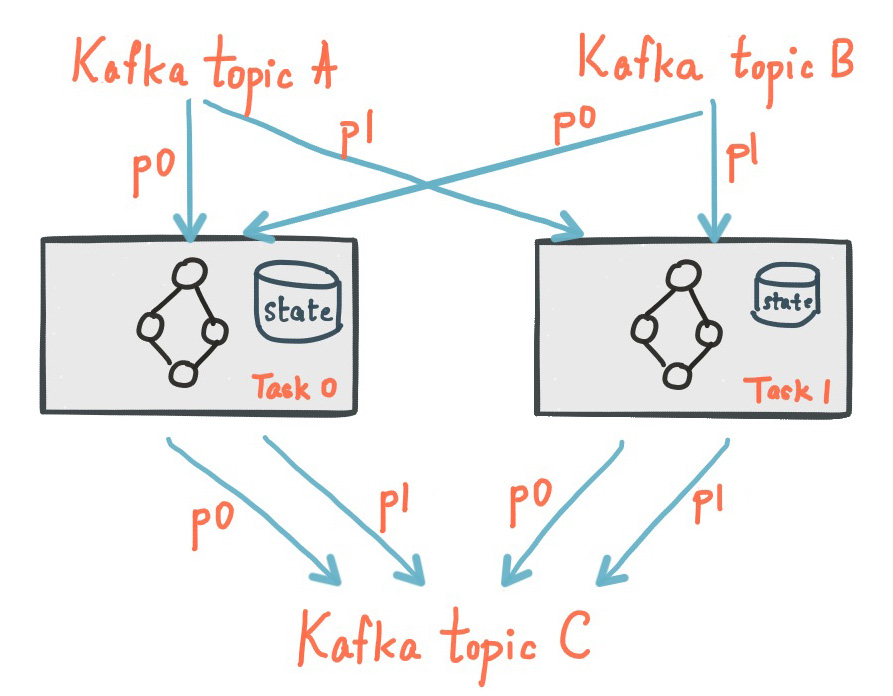
KafkaStreams의 Task들은 토폴로지를 시작하기 전에 State Store를 복구한다. 이 때 State Store 복구를 위해 사용되는 토픽이 changelog 토픽이다.
State Store를 복구한 이후에 토폴로지가 시작되므로 real time 환경에서는 State Store 복구 시간이 중요할 수 있다. 이 때 사용하는것이 Standby Task이다. Standby Task는 State Store 복구 시간을 단축시킴으로서 Task 초기화 과정을 단축시킨다.
예를 들어 어플리케이션이 Task1을 할당받지 못했다고 가정해보자. 하지만 어플리케이션이 Task1에 대한 Standby Task를 할당 받았다면 Standby Task는 Task1과 관련된 Changelog 토픽으로부터 데이터를 읽어와서 State Store를 미리 생성한다. 그리고 나중에 어플리케이션이 Task1을 할당받았다면 Standby Task가 어느정도 생성해놓은 State Store를 사용해서 복구작업을 시작한다.
Standby Task는 특정 Task에 대한 State Store를 미리 생성해놓음으로서 어플리케이션이 나중에 특정 Task를 할당 받았을때 Task의 초기화 작업 (State Store 복구작업)을 단축시킨다.
특징
StandbyTask 실행시점
StandbyTask가 실행되는 시점은 Active Task의 State Store가 모두 복구된 이후이다. 그 전까지는 Restore 컨슈머를 Active Task의 State Store를 복구하는데만 사용한다. Active Task의 State Store를 모두 복구한 이후에 StandbyTask가 Restore 컨슈머를 이용해서 State Store를 복구한다.
아직 State Store가 복구되지 않은 Active Task를 previous active task로 보는가?
그렇지 않다. Active Task라고 하더라도 running 상태만 previous active task로 들어간다. running 상태라는 것은 State Store가 복구되어 토폴로지가 동작중인 Task를 말한다. 따라서 State Store가 복구 중인 Active Task는 Previous Standby Task로 들어간다.
Standby Task를 넣으면 Topology가 동작하는데까지 시간이 단축 될 것인가?
단축은 될 것이다. 하지만 알아야할 점이 하나 있다. StreamThread에 할당된 Task들의 토폴로지가 실행되기 위해선 StreamThread에 할당된 모든 Task의 StateStore가 복구되어야 한다. 즉 StreamThread에 할당된 Task들 중에서 하나라도 StateStore가 복구되지 않으면 토폴로지가 실행되지 않는다. 따라서 특정 Task가 Standy 덕분에 State Store를 빠르게 복구 했다 하더라도 같은 StreamThread내의 다른 Task의 State Store가 복구 되지 않았다면 State Store의 복구가 완료될 때까지 토폴로지가 실행되지 않는다.
Standby 관련 속성
num.standby.replicas
Standy Replicas의 수이다. Standy Replicas라는 것은 State Store의 복사본이다. Kafka Stream은 명시된 수의 복사본을 생성하려고 시도한다. 그리고 가능한한 최신 상태로 유지하려고 한다. Standy Replicas는 장애 조치의 지연을 최소화하는데 사용된다. 만약에 특정 인스턴스가 다운되면 각각의 Task들은 standby replica를 가지고 있는 인스턴스에서 재실행 되도록 한다. 따라서 State Store를 복원하는데 걸리는 시간을 최소화할 수 있다. Kafka Stream이 standby replicas를 사용해서 어떻게 State Store 복원을 최소화하는지 더 자세히 알고 싶으면 State 섹션을 참고해라
Standy 복구 과정
TaskManager#updateNewAndRestoringTasks
boolean updateNewAndRestoringTasks() {
active.initializeNewTasks();
standby.initializeNewTasks();
final Collection<TopicPartition> restored = changelogReader.restore(active);
active.updateRestored(restored);
if (active.allTasksRunning()) {
Set<TopicPartition> assignment = consumer.assignment();
log.trace("Resuming partitions {}", assignment);
consumer.resume(assignment);
assignStandbyPartitions();
return true;
}
return false;
}
위의 코드는 Active Task의 State Store를 복구하는 코드이다. 위의 코드를 보면 알 수 있듯이 모든 Active Task들이 running 상태가 되어야만 메인 컨슈머를 이용해서 소스 토픽으로부터 데이터를 읽기 시작한다. running 상태라는 것은 State Store를 복구했다는 것이다.
또한 Active Task들이 모두 running 상태가 되면 assignStandbyPartitions() 메소드를 호출한다. assignStandbyPartitions() 메소드에서는 Restore 컨슈머에게 Changelog 토픽의 파티션을 할당하는 작업을 한다. 즉 모든 Task들이 running 상태가 되어야만 StandbyTask가 State Store를 복구하기 시작한다.
TaskManager#assignStandbyPartitions()
private void assignStandbyPartitions() {
// 1
final Collection<StandbyTask> running = standby.running();
final Map<TopicPartition, Long> checkpointedOffsets = new HashMap<>();
for (final StandbyTask standbyTask : running) {
checkpointedOffsets.putAll(standbyTask.checkpointedOffsets());
}
// 2
restoreConsumer.assign(checkpointedOffsets.keySet());
for (final Map.Entry<TopicPartition, Long> entry : checkpointedOffsets.entrySet()) {
// 3
final TopicPartition partition = entry.getKey();
final long offset = entry.getValue();
if (offset >= 0) {
restoreConsumer.seek(partition, offset);
} else {
restoreConsumer.seekToBeginning(singleton(partition));
}
}
}
위의 코드는 아래와 같은 순서로 진행된다.
- StandbyTask 중에서 running 상태인 StandbyTask들을 구한다. (이 시점에서는 할당된 모든 StandbyTask들이 running 상태가 되어있을 것이다) 그리고 StandbyTask에 할당된 모든 파티션과 그 파티션에 해당하는 체크포인트를 구한다. (이 파티션들은 Changelog 토픽의 파티션일 것이다)
- StandbyTask에 할당된 모든 파티션들을 Restore 컨슈머에게 할당한다.
- Checkpoint가 있는 경우에는 Checkpoint부터 데이터를 읽어오기 위해서 Consumer#seek 메소드를 사용한다. Checkpoint가 없는 경우에는 처음부터 데이터를 읽어온다.
StreamThread#maybeUpdateStandbyTasks(final long now)
private void maybeUpdateStandbyTasks(final long now) {
if (state == State.RUNNING && taskManager.hasStandbyRunningTasks()) {
if (processStandbyRecords) {
if (!standbyRecords.isEmpty()) {
final Map<TopicPartition, List<ConsumerRecord<byte[], byte[]>>> remainingStandbyRecords = new HashMap<>();
for (final Map.Entry<TopicPartition, List<ConsumerRecord<byte[], byte[]>>> entry : standbyRecords.entrySet()) {
final TopicPartition partition = entry.getKey();
List<ConsumerRecord<byte[], byte[]>> remaining = entry.getValue();
if (remaining != null) {
final StandbyTask task = taskManager.standbyTask(partition);
// 1
remaining = task.update(partition, remaining);
if (remaining != null) {
// 2
remainingStandbyRecords.put(partition, remaining);
} else {
// 3
restoreConsumer.resume(singleton(partition));
}
}
}
// 4
standbyRecords = remainingStandbyRecords;
log.debug("Updated standby tasks {} in {}ms", taskManager.standbyTaskIds(), time.milliseconds() - now);
}
processStandbyRecords = false;
}
try {
// 5
final ConsumerRecords<byte[], byte[]> records = restoreConsumer.poll(0);
if (!records.isEmpty()) {
for (final TopicPartition partition : records.partitions()) {
final StandbyTask task = taskManager.standbyTask(partition);
if (task == null) {
throw new StreamsException(logPrefix + "Missing standby task for partition " + partition);
}
// 6
final List<ConsumerRecord<byte[], byte[]>> remaining = task.update(partition, records.records(partition));
if (remaining != null) {
// 7
restoreConsumer.pause(singleton(partition));
standbyRecords.put(partition, remaining);
}
}
}
} catch (final InvalidOffsetException recoverableException) {
log.warn("Updating StandbyTasks failed. Deleting StandbyTasks stores to recreate from scratch.", recoverableException);
final Set<TopicPartition> partitions = recoverableException.partitions();
for (final TopicPartition partition : partitions) {
final StandbyTask task = taskManager.standbyTask(partition);
log.info("Reinitializing StandbyTask {}", task);
task.reinitializeStateStoresForPartitions(recoverableException.partitions());
}
restoreConsumer.seekToBeginning(partitions);
}
}
}
위의 코드는 StreamThread#maybeUpdateStandbyTasks 코드로 StandbyTask를 통해서 State Store를 업데이트하는 메소드이다. 이 메소드는 runOnce() 메소드에서 호출이 된다.
위의 메소드에 대한 설명은 아래와 같다.
우선 processStandyRecords에 따라서 실행되는 코드가 다르다. processStandyRecords가 true가 되는 경우는 commitInterval이 지나서 Task들을 commit할 때이다. Task들의 commit은 StreamThread#maybeCommit(final long now) 메소드에서 일어난다. StreamThread#maybeCommit 메소드에서 processStandyRecords를 true로 세팅한다.
processStandyRecords가 true인 경우
- Map<TopicPartition, List<ConsumerRecord<byte[], byte[]»> standbyRecords는 State Store에 아직 업데이트를 하지 못한 Records들이다. 파티션별 업데이트 해야 할 레코드들을 순회해면서 StandbyTask#update(final TopicPartition partition, final List<ConsumerRecord<byte[], byte[]» records) 메소드를 호출한다. 이 메소드는 Changelog 토픽의 레코드들을 사용해서 State Store를 업데이트한다.
- StandbyTask#update의 리턴값은 업데이트를 하지 못한 레코드들이다. 업데이트를 하지 못한 레코드가 있다면 remainingStandbyRecords에 추가한다.
- 업데이트를 하지 못한 레코드가 없다면, 즉 모든 레코드를 업데이트 했다면 Consumer#resume 메소드를 통해서 해당 파티션의 데이터를 읽어오도록 한다.
- standbyRecords를 remainingStandbyRecords로 세팅한다. 즉 standbyRecords는 아직 업데이트를 하지 못한 레코드들이다.
공통 부분
- Consumer#poll 메소드를 통해서 레코드를 읽어온다. 만약에 standbyRecords에 업데이트를 아직 하지 못한 레코드들이 남아있는 상태라면 해당 파티션은 pause되어 있을 것이다. 따라서 standbyRecords에 업데이트를 하지 못한 레코드들이 없는 파티션의 레코드만 가져올 것이다.
- 파티션별로 레코드들을 순회하면서 StandbyTask#update 메소드를 통해서 State Store를 업데이트한다.
- 만약에 업데이트를 하지 못한 레코드가 있다면 해당 파티션을 pause한다. 그리고 standbyRecords에 업데이트를 하지 못한 레코드들을 추가한다.
ProcessorStateManager#updateStandbyStates
StandbyTask#update 메소드는 사실상 ProcessorStateManager#updateStandbyStates만 호출하고 있다. ProcessorStateManager#updateStandbyStates 메소드에서는 Changelog 토픽의 레코드를 가지고 State Store를 업데이트 한다. 아래는 이에 대한 코드이다.
List<ConsumerRecord<byte[], byte[]>> updateStandbyStates(final TopicPartition storePartition,
final List<ConsumerRecord<byte[], byte[]>> records) {
final long limit = offsetLimit(storePartition);
List<ConsumerRecord<byte[], byte[]>> remainingRecords = null;
final List<KeyValue<byte[], byte[]>> restoreRecords = new ArrayList<>();
// restore states from changelog records
// 1
final BatchingStateRestoreCallback restoreCallback = getBatchingRestoreCallback(restoreCallbacks.get(storePartition.topic()));
long lastOffset = -1L;
int count = 0;
// 2
for (final ConsumerRecord<byte[], byte[]> record : records) {
if (record.offset() < limit) {
restoreRecords.add(KeyValue.pair(record.key(), record.value()));
lastOffset = record.offset();
} else {
if (remainingRecords == null) {
remainingRecords = new ArrayList<>(records.size() - count);
}
remainingRecords.add(record);
}
count++;
}
if (!restoreRecords.isEmpty()) {
try {
// 3
restoreCallback.restoreAll(restoreRecords);
} catch (final Exception e) {
throw new ProcessorStateException(String.format("%sException caught while trying to restore state from %s", logPrefix, storePartition), e);
}
}
// 4
// record the restored offset for its change log partition
restoredOffsets.put(storePartition, lastOffset + 1);
// 5
return remainingRecords;
}
- 레코드을 가지고 State Store를 복구하는 콜백 메소드를 구한다.
- 레코드들을 순회하면서 해당 레코드의 오프셋이 limit가 넘었는지 확인한다. limit를 넘지 않았다면 restoreRecords에 추가되고 만약에 limit를 넘었다면 remainingRecords에 추가한다.
- BatchingStateRestoreCallback restoreCallback의 restoreAll 메소드를 호출해서 State Store를 업데이트한다.
- Map<TopicPartition, Long> restoredOffsets 필드를 업데이트한다. restoredOffsets는 각 changelog 파티션별로 가장 최근에 State Store에 업데이트한 레코드의 오프셋을 저장한다.
- remainingRecords를 리턴한다. remainingRecords는 State Store에 업데이트가 아직 안된 레코드들이다.
여기서 limit을 정하는 방법이 굉장히 중요해보인다. 왜냐하면 limit까지만 State Store를 업데이트하기 때문이다. 따라서 limit에 따라서 Standby의 업데이트 속도가 결정날것으로 보인다.
offsetLimit
위의 코드를 보면 limit 보다 작은 오프셋 레코드만 State Store에 업데이트 하기 때문에 limit가 Standby Task 속도에 영향을 줄 것으로 보인다.
아래 코드가 offsetLimit(final TopicPartition partition) 메소드이다. offsetLimits는 키가 TopicPartition이고 Value가 Long (OffsetLimit)인 HashMap이다. 아래 코드에서 보면 알 수 있듯이 파티션에 해당하는 offsetLimit이 있으면 그 값을 리턴하고 없으면 Long.MAX_VALUE를 리턴한다.
ProcessorStateManager#offsetLimit
private long offsetLimit(final TopicPartition partition) {
final Long limit = offsetLimits.get(partition);
return limit != null ? limit : Long.MAX_VALUE;
}
ProcessorStateManager#putOffsetLimit
아래의 코드는 putOffsetLimit(final TopicPartition partition, final long limit) 메소드로 offsetLimits를 업데이트할 때 호출되는 메소드이다. 이 메소드를 통해서 offsetLimits를 업데이트 한다.
void putOffsetLimit(final TopicPartition partition, final long limit) {
log.trace("Updating store offset limit for partition {} to {}", partition, limit);
offsetLimits.put(partition, limit);
}
그럼 위에 메소드는 언제 호출이 될까? 즉 언제 offsetLimits가 업데이트 될까? 코드로 확인해보니 offsetLimits가 업데이트 되는 시점은 아래와 같다. (정확하지 않을수 있다)
- StreamTask가 Commit되는 시점
- StandbyTask가 Commit되는 시점
- StandbyTask가 Resume되는 시점
- StreamTask의 initializeStateStores() 메소드가 호출되는 시점
- StandbyTask의 initializeStateStores() 메소드가 호출되는 시점
즉 위와 같은 시점에 offsetLimits가 업데이트 된다. 그리고 StreamTask가 Commit되는 시점을 제외하고 나머지는 AbstractTask#updateOffsetLimits 메소드를 통해서 offsetLimits을 업데이트한다. 아래 메소드에서 partitions는 Task에 할당된 파티션이다. 이 파티션은 소스 토픽 파티션이지 Changelog 토픽 파티션이 아니다. 즉 updateOffsetLimits 메소드를 통해서는 Changelog 토픽 파티션의 offsetLimits가 업데이트 되지 않는다.
AbstractTask#updateOffsetLimits()
protected void updateOffsetLimits() {
for (final TopicPartition partition : partitions) {
try {
final OffsetAndMetadata metadata = consumer.committed(partition);
final long offset = metadata != null ? metadata.offset() : 0L;
stateMgr.putOffsetLimit(partition, offset);
// skip
}
// skip
}
}
마찬가지로 StreamTask가 Commit되는 시점에 업데이트되는 offsetLimits도 소스 토픽 파티션에 대한 offsetLimits이다. 따라서 이 경우에도 Changelog 토픽의 파티션에 대한 offsetLimits는 업데이트 되지 않는다.
사실 코드상으로나 디버깅을 해봐도 Changelog 토픽 파티션에 대한 offsetLimits가 업데이트 되는 시점을 찾지 못했다. 따라서 항상 Changelog 토픽 파티션에 대한 offsetLimits는 Long.MAX_VALUE가 된다. (이전에 설명했듯이 파티션에 해당하는 offsetLimits가 없는 경우에는 Long.MAX_VALUE를 리턴한다)
결과적으로 offsetLimits로 인해서 Standby Task의 속도가 느려지거나 하는 일은 없을것으로 보인다.