병행성
by Gunju Ko
이 글은 “이펙티브 자바” 책 내용을 정리한 글입니다.
만약 저작권 관련 문제가 있다면 “gunjuko92@gmail.com”로 메일을 보내주시면, 바로 삭제하도록 하겠습니다.
10장 병행성
규칙 66 변경 가능 공유 데이터에 대한 접근은 동기화하라
synchronized
- synchronized 키워드는 특정 메서드나 코드 블록을 한 번에 한 스레드만 시용하도록 보장한다. 동기화 메커니즘을 적절히 사용하기만 하면, 모든 메소드가 항상 객체의 일관된 상태만 보도록 만들 수 있다.
- mutually exclusive : 다른 스레드가 변경 중인 객체의 상태를 관측할 수 없어야한다.
- 동기화 없이는 한 스레드가 만든 변화를 다른 스레드가 확인할 수 없다. 동기화는 스레드가 일관성이 깨진 객체를 관측할 수 없도록 할 뿐 아니라, 동기화 메소드나 동기화 블록에 진입한 스레드가 동일한 락의 보호 아래 이루어진 모든 변경의 영향을 관측할 수 있도록 보장한다.
스레드 간의 안정적 통신을 위해서도 동기화는 반드시 필요하다
- 자바 언어 명세에는 long이나 double이 아닌 모든 변수는 원자적으로 읽고 쓸 수 있다고 되어 있다. 다시 말해, long이나 double이 아닌 변수를 읽으면 나오는 값은 항상 어떤 스레드가 저장한 값이라는 것이다. 설사 여러 스레드가 그 변수를 동기화 없이 변경했다고 해도 말이다.
- 성능을 높이기 위해서는 원자적 데이터를 읽거나 쓸 때 동기화는 피해야 한다는 이야기를 아마 들어보았을 것이다. 아주 위험한 이야기다. 언어 명세상으로는 필드에서 읽어낸 값은 임의의 값이 될 수 없다고 되어 있으나, 그렇다고 어떤 스레드가 기록한 값을 반드시 다른 스레드가 보게 되리라는 보장은 없다. 상호배제성뿐 아니라 스레드 간의 안정적 통신을 위해서도 동기화는 반드시 필요하다.
- 자바 언어 명세의 일부인 메모리 모델 때문이다. 메모리 모델은 한 스레드가 만든 변화를 다른 스레드가 볼 수 있게 되는 시점과, 그 절차를 규정한다.
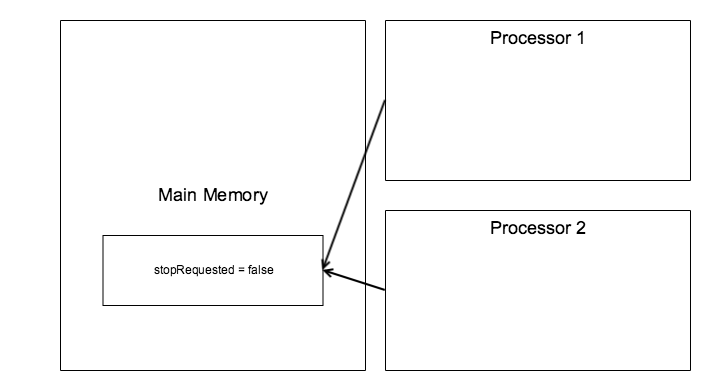
메모리 모델 두 개의 스레드가 stopRequested라는 boolean 필드를 공유하고 있다고 해보자. 만약 두 개의 스레드가 서로 다른 프로세서에서 실행된다면, 각 스레드는 stopRequested의 로컬 카피를 각각 가지게 된다. 만약에 한 스레드가 값을 변경하면, 변경 내용이 메인 메모리에 있는 원래 값에 즉시 반영되지 않을 수 있다. 이는 캐시에 write policy에 따라 다르다.
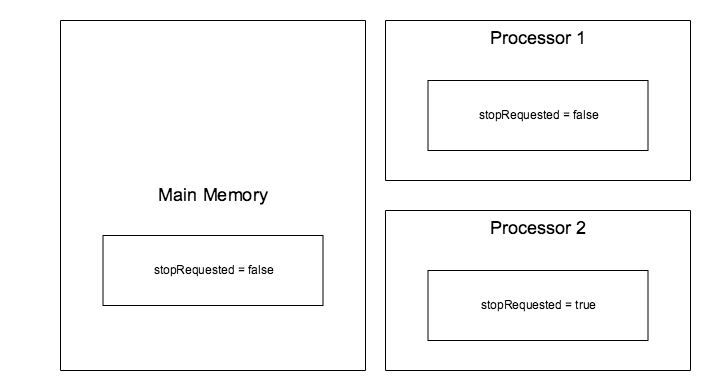
동기화 절차 없이 공유 필드에 쓰는 작업을 한다면, 어떤 프로세서에서 실행되느냐에 따라서 공유 필드의 값이 다를 수 있다. 자바의 synchronized는 mutual exclusion과 visibility를 모두 보장해준다. 공유 변수의 값을 수정하는 코드 블록을 동기화(synchronized)하면 하나의 스레드만 코드 블록을 실행 할 수 있으며 변경된 내용은 메인 메모리에 반영된다. 어떤 경우에는 Atomic이 아니라 Visibility만 원할 수 있습니다. 이러한 상황에서 동기화를 사용하면 성능이 떨어진다. 이 떄 Volatile을 사용하면 된다. Volatile은 Atomic은 보장해주지 않지만, Visibility는 보장해준다. Volatile 변수의 값은 절대 캐시되지 않으며 모든 쓰기 및 읽기는 메인 메모리에서 수행된다.
출처
- https://www.geeksforgeeks.org/volatile-keyword-in-java/
- http://tutorials.jenkov.com/java-concurrency/volatile.html
private static boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(new Runnable() {
@Override
public void run() {
int i = 0;
while (!stopRequested)
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
- 이 프로그램의 문제는 동기화 메커니즘을 적용하지 않은 탓에 main 스레드가 변경한 stopRequest의 새로운 값을 백그라운드 스레드가 언제쯤 보게 될지 알 수 없다는 것이다. 그 덕에 생기는 문제가 바로 생존 오류 (liveness failure)다. 살아 있기는 하나 더 진행하지 못하는 프로그램이 되는 것이다.
- 변경 가능한 공유 데이터에 대한 접근을 동기화하지 않았을 때 생길 수 있는 결과는, 그 데이터가 원자적으로 읽고 쓸 수 있는 데이터라 해도 심각하다.
stopRequest 필드를 동기화해라
- 이 문제를 수정하는 한가지 방법은 stopRequest 필드를 동기화하는 것이다.
private static boolean stopRequested;
private static synchronized void requestStop() {
stopRequested = true;
}
private static synchronized boolean stopRequested() {
return stopRequested;
}
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(new Runnable() {
@Override
public void run() {
int i = 0;
while (!stopRequested())
i++;
System.out.println("Thread is stopped");
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
requestStop();
System.out.println("Thread should be stop!");
}
- 쓰기 메서드와 읽기 메소드에 동기화 메커니즘이 적용되었음에 유의하자. 쓰게 메서드만 동기화하는 것으로는 충분치 않다! 사실 읽기 연산과 쓰기 연산에 전부 적용하지 않으면 동기화는 아무런 효과도 없다
- 사실 requestStop(), stopRequested() 메소드는 동기화 없이도 원자적이다. 다시 말해서, 이들 메소드에 동기화를 적용한 것은 상호 배재성을 달성하기 위해서가 아니라 순전히 스레드간 통신 문제를 해결하기 위해서였다는 것이다.
동기화 대신 volatile을 사용해도 된다.
- 좋은 성능을 내면서 간결하기까지 한 대안이 있다. 위 코드에 사용된 boolean 필드 stopRequested를 volatile로 선언하는 것이다. 그러면 락은 없어도 된다. 비록 volatile이 상호 배제성을 실현하진 않지만, 어떤 스레드건 가장 최근에 기록된 값을 읽도록 보장한다.
private static volatile boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(new Runnable() {
@Override
public void run() {
int i = 0;
while (!stopRequested)
i++;
System.out.println("Thread is stopped");
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
System.out.println("Thread should be stop!");
}
- volatile을 사용할 때는 주의해야한다. 아래의 메소드를 보자.
private static volatile int nextSerialNumber = 0;
public static int generateSerialNumber() {
return nextSerialNumber++;
}
- 이 메소드의 상태를 구성하는 것은 원자적으로 접근 가능한 필드 nextSerialNumber이며, 이 필드가 가질 수 있는 값은 전부 유효하다. 따라서 불변식을 보호하기 위해 동기화 메커니즘을 사용할 필요가 없다. 그런데 동기화 없이는 제대로 동작하지 않는다.
- 문제는 증가 연산다 ++가 원자적이지 않다는 데 있다. 이 연산자는 nextSerialNumber 필드에 두 가지 연산을 순서대로 시행한다.
- 먼저 값을 읽는다.
- 그 다음에 새로운 값, 즉 읽은 값 더하기 1을 필드에 쓴다.
- 첫 번째 스레드가 필드의 값을 읽은 후 새 값을 미쳐 기록하기 전에 두 번째 스레드가 필드에서 같은 값을 읽으면, 두 스레드는 같은 일련번호를 얻게 된다. 이것이 안전 오류 (safety failure)다. 프로그램이 잘못된 결과를 계산하는 것이다.
- 이 문제를 해결하는 한 가지 방법은, 메소드를 synchronized로 선언하는 것이다.
- 더 좋은 방법은 AtomicLong 클래스를 쓰는 것이다. 이 클래스는 java.util.concurrent.atomic의 일부다. 원하는 일을 해주면서도, synchronized 키워드를 사용한 해법보다 성능도 좋다.
private static AtomicInteger atomicNextSerialNumber = new AtomicInteger(0);
public static int generateAtomicSerialNumber() {
return atomicNextSerialNumber.getAndIncrement();
}
변경 가능 데이터를 공유하지 말아라
- 동기화 관련 문제를 피하는 가장 좋은 방법은 변경 가능 데이터를 공유하지 않는 것이다.
- 굳이 공유를 해야겠다면 변경 불가능 데이터를 공유하거나, 그럴 필요가 없다면 아예 공유하지 마라.
- 다시 말해서, 변경 가능 데이터는 한 스레드만 이용하도록 하라는 것이다 단 이 지침을 따를 때는 그 사실을 문서로 남겨 놓도록 해야한다.
요약하자면, 변경 가능한 데이터를 공유할 때는 해당 데이터를 읽거나 쓰는 모든 스레드는 동기화를 수행해야 한다는 것이다. 변경 가능 데이터를 적절히 동기화하지 않으면 생존 오류나 안전 오류가 생긴다. 이는 가장 디버깅하기 까다로운 오류들이다. 이런 오류들은 간헐적이고, 타이밍에 민감하다. 이런 오류가 있는 프로그램들은 어떤 VM에서 돌리느냐에 따라 극도로 다르게 동작하기도 한다.
규칙 67 과도한 동기화는 피하라
- 동기화를 너무 과도하게 적용하면 성능 저하, deadlock, 비결정적 동작(nondeterministic behavior) 등의 문제가 생길 수 있다.
- 생존 오류나 안전 오류를 피하고 싶으면, 동기화 메서드나 블록 안에서 클라이언트에게 프로그램 제어 흐름(control)을 넘기지 마라. 다시 말해서, 동기화가 적용된 영역 안에서는 재정의 가능 메소드나 클라이언트가 제공한 함수 객체 메소드를 호출하지 말라는 것이다. 동기화 영역이 존재하는 클래스 관점에서 보면, 그런 메소드는 불가해 메소드다. 무슨 일을 하는지 알 수 없고, 제어할 수도 없다. 불가해 메소드가 어떤 일을 하는냐에 따라, 동기화 영역 안에서 호출하게 되면 예외나 교착상태, 데이터 훼손이 발생할 수 있다.
- 자바가 제공하는 락은 재진입 가능하다 (reentrant) 이미 락을 들고 있는 상태에서, 또 다시 락을 획득하려고 해도 성공한다. 락이 보호하는 데이터에 대해 개념적으로 관련성 없는 작업이 진행 중인데도 말이다. 이것 때문에 실로 참혹한 결과가 빚어지게 될 수도 있다. 본질적으로 말해서, 락이 제 구실을 못하게 된 것이다. 재진입 가능 락은 객체 지향 다중 스레드 프로그램을 쉽게 구현할 수 있도록 하지만, 생존 오류를 안전 오류로 변모시킬 수도 있다.
- 불가해 메소드를 호출하는 부분을 동기화 영역 밖으로 옮겨라. 동기화 영역 바깥에서 불가해 메소드를 호출하는 것을 열린 호출 (open call)이라고 한다. 오류를 방지할 뿐 아니라, 병행성을 대단히 높여주는 기법이다. 불가해 메소드의 수행 시간은 제멋대로 길어질 수 있다. 동기화 지역 안에서 그런 메소드를 호출하면, 다른 스레드는 쓸데없이 오랜 시간 동안 락이 풀리기를 기다려야 할 것이다.
- 명심해야 할 것은, 동기화 영역 안에서 수행되는 작업의 양을 기능한 한 줄여야 한다는 것이다.
- static 필드를 변경하는 메소드가 있을 때는 해당 필드에 대한 접근을 반드시 동기화해야 한다. 보통 한 스레드만 이용하는 메소드라 해도 그렇다. 클라이언트 입장에서는 그런 메소드에 대한 접근을 외부적으로 동기화할 방법이 없다. 다른 클라이언트가 무슨 짓을 할지 알 수 없기 때문이다.
성능
- 변경 가능 클래스의 경우, 병렬적으로 이용될 클래스이거나, 내부적인 동기화를 통해 외부에서 전체 객체에 락을 걸 때보다 높은 병행성을 달성할 수 있을 때만 스레드 안정성을 갖도록 구현해야 한다. 그렇지 않다면 내부적인 동기화는 하지 마라. 필요할 때, 클라이언트가 객체 외부적으로 동기화를 하도록 두라
- StringBuffer 객체는 거의 항상 한 스레드만 이용하는 객체인데도 내부적으로 동기화를 하도록 구현되어 있다. 그래서 결국 StringBuilder로 대체된 것이다.
- 어떻게 해야 할지 잘 모르겠다면, 클래스 내부적으로 동기화를 하는 대신 “스레드 안정성을 보장하지 않는 클래스”라고 문서에 남겨두자.
- 클래스 내부적으로 동기화 메커니즘을 적용해야 한다면, 락 분할(lock splitting), 락 스트라이핑(striping), 비봉쇄형 병행성 제어(nonblocking concurrency control)처럼 높은 병행성을 달성하도록 돕는 다양한 기법을 활용할 수 있다.
요약
데드락과 데이터 훼손 문제를 피하려면 동기화 영역안에서 불가해 메소드는 호출하지 말아라. 일반적으로 말하자면, 동기화 영역 안에서 하는 작업의 양을 제한하라는 것이다. 변경 가능 클래스를 설계할 때는, 내부적으로 동기화를 처리해야 하는지 살펴보라. 타당한 이유가 있을 때만 내부적으로 동기화하고, 어떤 결정을 내렸는지를 문서에 명확하게 밝혀두라
규칙 68 스레드보다는 실행자와 태스크를 이용하라
- 릴리스 1.5부터 자바 플랫폼에는 java.util.concurrent가 추가되었다. 이 패키지에는 실행자 프레임워크(Executor Framework)라는 것이 들어 있는데, 유연성이 높은 인터페이스 기반 태스크(task) 실행 프레임워크다.
- ExecutorService로 할 수 있는 일은 많다. 예를 들어, 특정 태스크가 종료되기를 기다릴 수도 있고, 임의의 태스크들이 종료되기를 기다릴 수도 있다. ExecutorService가 자연스럽게 종료되기를 기다릴 수도 있으며, 태스크가 끝날 때마다 그 결과를 차례로 가져올 수도 있다. 이 외에도 많다.
- 큐의 작업을 처리하는 스레드를 여러 개 만들고 싶을 때는 스레드 풀이라 부르는 실행자 서비스를 생성하는 정적 팩터리 메소드를 이용하면 된다. 스레드풀에 담기는 스레드 숫자는 고정시켜 놓을 수도 있고, 가변적으로 변하도록 설정할 수도 있다. Executors 클래스에는 필요한 실행자 대부분을 생성할 수 있도록 하는 정적 팩토리 메소드들이 들어 있다.
- ThreadPoolExecutor 클래스를 직접 이용할 수도 있다. 이 클래스를 이용하면 스레드 풀의 동작을 거의 모든 측면에서 세밀하게 제어할 수 있다.
- 작은 프로그램이거나 부하가 크지 않은 서버를 만들 때는 보통 Executors.newCachedThreadPool이 좋다. 캐시 기반 스레드 풀의 경우, 작업은 큐에 들어가는 것이 아니라 실행을 담당하는 스레드에 바로 넘겨진다. 가용한 스레드가 없는 경우에는 새 스레드가 만들어진다. 따라서 부하가 심한 서버에서 사용하는것은 부적절하다.
- 부하가 심한 환경에 들어갈 서버를 만들 때는 Executors.newFixedThreadPool을 이용해서 스레드 개수가 고정된 풀을 만들거나, 최대한 많은 부분을 직접 제어하기 위해 ThreadPoolExecutor 클래스를 사용하는 것이 좋다.
- 작업 큐를 손수 구현하는 것은 삼가야 할 뿐 아니라, 일반적으로는 스레드를 직접 이용하는 것도 피하는 것이 좋다.
- Thread는 작업의 단위였을 뿐 아니라 작업을 실행하는 메커니즘이기도 했다. 하지만 이제 Thread는 더 이상 중요하지 않다. 작업과 실행 메커니즘이 분리된 것이다. 중요한 것은 작업의 단위이며, 태스크라 부른다. 태스크에는 두 가지 종류가 있다.
- Runnable, Callable
- Callable은 Runnable과 비슷하지만 값을 반환한다.
- 태스크를 실행하는 일반 메커니즘은 실행자 서비스 (Executor Service)다. 태스크와 실행자 서비스를 분리해서 생각하게 되면 실행 정책을 더욱 유연하게 정할 수 있게 된다. 핵심은, 실행자 프레임워크는 태스크를 실행하는 부분을 담당한다.
- 실행자 프레임워크에는 Timer를 대신할 ScheduledThreadPoolExecutor도 정의되어 있다. Timer 보다 사용하기 편리할 뿐 아니라, 유연성도 훨씬 높다. ScheduledThreadPoolExecutor는 여러 스레드를 이용할 뿐 아니라, 태스크 안에서 무점검 예외가 발생한 상황도 우아하게 복구한다.
ThreadPoolExecutor의 corePoolSize, maxPoolSize ThreadPoolExecutor의 corePoolSize와 maxPoolSize는 아래와 같은 규칙을 따른다.
- 스레드의 수가 corePoolSize보다 작은 경우, 무조건 새로운 스레드를 생성하고 태스크를 실행한다.
- 스레드의 수가 corePoolSize보다 크거나 같은 경우, 태스크를 큐에 넣는다.
- 큐가 가득차고 스레드의 수가 maxPoolSize보다 작은 경우 새로운 스레드를 생성하고 태스크를 실행한다.
- 큐가 가득차고 스레드의 수가 maxPoolSize와 같은 경우, 태스크를 거절한다. (RejectedExecutionException 예외가 발생)
여기서 중요한점은 큐가 가득찬 경우에만 maxPoolSize까지 스레드 수를 늘린다는 것이다. 따라서 unbounded queue를 사용한다면, 스레드의 수는 corePoolSize까지만 늘어난다.
규칙 69 wait나 notify 대신 병행성 유틸리티를 이용하라
- 릴리스 1.5부터 자바 플랫폼에는 고수준 병행성 유틸리티들이 포함되어, 예전에는 wait와 notify를 사용해 구현해야만 했던 일들을 대신한다. wait와 notify를 정확하게 사용하는 것이 어렵기 때문에, 이 고수준 유틸리티들을 반드시 이용해야 한다.
- Java.util.concurrent에 포함된 유틸리티들은 아래와 같이 세가지 범주로 나눌 수 있다.
- 실행자 프레임워크
- 병행 컬렉션
- 동기자
- 병행 컬렉션은 List, Queue, Map 등의 표준 컬렉션 인터페이스에 대한 고성능 병행 컬렉션 구현을 제공한다. 이 컬렉션들은 병행성을 높이기 위해 동기화를 내부적으로 처리한다. 따라서 컬렉션 외부에서 병행성을 처리하는 것은 불가능하다. 락을 걸어봐야 아무 효과가 없을 뿐 아니라 프로그램만 느려진다.
- 확실한 이유가 없다면 Collections.synchronizedMap이나 HashTable 대신 ConcurrentHashMap을 사용하도록 하자. 구식이 되어버린 동기화 맵을 병행 맵으로 바꾸기만 해도 병렬 프로그램의 성능은 극적으로 개선된다.
- 컬렉션 인터페이스 기운데 몇몇은 봉쇄 연산(blocking operation)이 기능하도록 확장되었다. 성공적으로 수행될 수 있을 때까지 대기(wait)할 수 있도록 확장되었다는 것이다. 예를 들어 BlockingQueue는 Queue를 확장해서 take 같은 연산을 추가하였다. take는 큐의 맨 앞 원소를 제거한 다음 반환하는데, 큐가 비어있는 경우에는 대기한다.
- 동기자(synchronizer)는 스레드들이 서로를 기다릴 수 있도록 하여, 상호협력이 가능하게 한다. 가장 널리 쓰이는 동기자로는 CountDownLatch와 Semaphore가 있다. 사용 빈도는 낮지만 CyclicBarrier나 Exchanger 같은 것도 쓰인다.
- 카운트다운 래치(countdown latch)는 일회성 배리어(barrier)로서 하나 이상의 스레드가 작업을 마칠 때까지 다른 여러 스레드가 대기할 수 있도록 한다. CountDownLatch에 정의된 유일한 생성자는 래치의 countdown 메소드가 호출될 수 있는 횟수를 나타내는 int 값을 인자로 받는다. 대기중인 스레드가 진행할 수 있으려면 그 횟수 만큼 countdown 메소드가 호출되어야 한다.
- wait 메서드를 호출할 때는 반드시 이 대기 순환문(wait loop) 숙어대로 하자. wait 호출 전에 조건을 검사하고, 조건이 만족되었을 때는 wait을 호출하지 않도록 하는 것은 생존 오류를 피하려면 필요한 부분이다. wait가 실행되고 나서 다시 wait를 호출하기 전에 조건을 검사하는 것은 안전 오류를 피하기 위해서이다.
synchronized (obj) {
while (<이 조건이 만족되지 않을 경우에 순환문 실행>)
obj.wait() // 락 해제, 깨어나면 다시 락 획득
...
// 조건이 만족되면 그에 맞는 작업 실행
}
- notify는 대기 중인 스레드가 있다는 가정하에서 하나만 깨우지만, notifyAll은 전부 다 각성시킨다. notify 보다는 notifyAll를 사용해라. 깨어날 필요가 없는 스레드도 꺠어날 것이지만 프로그램의 정확성에는 영향을 끼치지 않는다. 대기 조건이 false인 것을 확인하고나면 바로 다시 대기 상태로 돌아갈 것이다. notifyAll을 사용하면 다른 스레드가 우연히, 또는 악의적으로 wait를 호출하는 상황에 대비할 수 있다. 아주 중요한 notify를 그런 스레드가 “삼켜버리면” 정말로 실행되어야 하는 스레드들은 무한히 대기하게 될 수도 있다.
- 새로 만드는 프로그램에 wait나 notify를 사용할 이유는 거의 없다.
규칙 70 스레드 안전성에 대해 문서로 남겨라
- 병렬적으로 사용해도 안전한 클래스가 되려면, 어떤 수준의 스레드 안전성을 제공하는 클래스인지 문서에 명확하게 남겨야 한다.
- 스레드 안전성을 그 수준별로 요약
- 변경 불가능(immutable) : 이 클래스로 만든 객체들은 상수다. 따라서 외부적인 동기화 메커니즘 없이도 병렬적 이용이 가능하다. String, Long, BigInteger 등이 그 예다.
- 무조건적 스레드 안전성(unconditionally thread-safe) : 이 클래스의 객체들은 변경이 가능하지만 적절한 내부 동기화 메커니즘을 갖추고 있어서 외부적으로 동기화 메커니즘을 적용하지 않아도 병렬적으로 사용할 수 있다. Random, ConcurrentHashMap 같은 클래스가 그 예다.
- 조건부 스레드 안전성(Conditionally thread-safe) : 무조건적 스레드 안정성과 거의 같은 수준이나 몇몇 스레드는 외부적 동기화가 없이는 병렬적으로 사용할 수 없다. Collections.synchronized 계열 메소드가 반환하는 포장 객체가 그 사례다. 이런 객체의 반복자는 외부적 동기화 없이는 병렬적으로 이용할 수 없다.
- 스레드 안전성 없음 : 이 클래스의 객체들은 변경 가능하다. 해당 객체들을 병렬적으로 사용하려면 클라이언트는 메소드를 호출하는 부분을 클라이언트가 선택한 외부적 동기화 수단으로 감싸야한다.
- 다중 스레드에 적대적(thread-hostile) : 이런 클래스의 객체는 설사 메소드를 호출하는 모든 부분을 외부적 동기화 수단으로 감싸더라도 안전하지 않다. 이런 클래스가 되는 것은 보통, 동기화없이 정적 데이터(static data)를 변경하기 때문이다.
- 다른 객체에 대한 뷰 역할을 하는 객체의 경우, 클라이언트는 원래 객체에 대해 동기화를 해야한다. 동기화 없이 직접 변경하는 일을 막기 위해서다.
Map<String, String> map = Collections.synchronizedMap(new HashMap<>());
Set<String> keys = map.keySet();
synchronized (map) {
for (String key : keys) {
// do something
}
}
- 맵에 대한 컬렉션 뷰를 순회할 때는 수동적으로 원래 맵에 동기화하도록 하라. 이 지침을 따르지 않을 경우 프로그램은 비결정적으로(non-deterministric) 동작할 수 있다.
- 무조건 스레드 안정성을 제공하는 클래스를 구현하는 중이라면 메소드를 synchronized로 선언하는 대신 private 락 객체를 이용하면 어떨지 따져보자. 이런 락 객체를 이용하면 클라이언트나 하위 클래스가 동기화에 개입하는 것을 막을 수 있고, 다음번 릴리즈에는 좀 더 복잡한 병행성 제어 전략도 쉽게 채택할 수 있게 된다.
- 메소드에 synchronized 키워드를 붙이는 것은 자기 자신을 락으로 이용하는 것이다. 따라서 동기화 메소드를 사용하는 것은 외부로 락을 공개하는 것과 다름없다. 따라서 클라이언트가 객체의 동기화 메커니즘에 개입할 수 있다.
public synchronized void method1() {
// do something
}
public void method1() {
synchronized(this) {
// do something
}
}
규칙 71 초기화 지연은 신중하게 하라
- 초기화 지연은 필드 초기화를 실제로 그 값이 쓰일 때까지 미루는 것이다. 값을 사용하는 곳이 없다면 필드는 결코 초기화되지 않을 것이다. 초기화 지연 기법은 기본적으로 최적화 기법이지만, 클래스나 객체 초기화 과정에서 발생하는 해로운 순환성(circularity)을 해소하기 위해서도 사용한다.
- 초기화 지연을 적용할 때 따라야 할 최고의 지침은 “정말로 필요하지 않으면 하지 마라”는 것이다. 초기화 지연 기법은 양날의 검이다.
- 초기화 지연 기법이 어울리는 곳은 따로 있다. 필드 사용 빈도가 낮고 초기화 비용이 높다면 쓸만할 것이다. 정말로 그런지 확실히 아는 방법은 초기화 지연 적용 전후의 성능을 비교해 보는 것이다. 대부분의 경우, 지연된 초기화를 하느니 일반 초기화를 하는 편이 낫다
- 초기화 순환성(initialization circularity) 문제를 해소하기 위해서 초기화를 지연시키는 경우에는 동기화된 접근자(synchronized accessor)를 사용하라. 가장 간단하고 명확한 방법이다.
private FieldType field;
synchronized FieldType getField() {
if (field == null)
field = computeFieldValue();
return field;
}
- 성능 문제 때문에 정적필드 초기화를 지연시키고 싶올 때는 초기화 지연 담당 클래스(lazy initialization holder class) 숙어를 적용하라. 클래스는 실제로 사용되는 순간에 초기화 된다는 점을 이용한 것이다.
private static class FieldHolder {
static final FieldType field = computeFieldValue();
}
static FieldType getField() {
return FieldHolder.field;
}
- FieldHolder 클래스는 getField 메소드가 처음으로 호출되는 순간에 초기화된다. 이 숙어가 좋은 점은 getField를 동기화 메소드로 선언하지 않아도 된다는 것이다. 최신 VM은 클래스를 초기화하기 위한 필드 접근은 동기화한다. 하지만 클래스가 일단 초기화되고 나면 코드를 바꿔서 앞으로의 필드 접근에는 어떤 동기화나 검사도 필요치 않도록 만든다.
- 성능 문제 때문에 객체 필드 초기화를 지연시키고 싶다면 이중 검사(double-check) 숙어를 사용하라. 이 숙어를 사용하면 초기화가 끝난 필드를 이용하기 위해 락을 걸어야 하는 비용을 없앨 수 있다. 이미 초기화된 필드에는 락을 걸지 않으므로, 필드는 반드시 volatile로 선언해야 한다.
private volatile FieldType field;
FieldType getField() {
FieldType result = field;
if (result == null) {
synchronized(this) {
result = field;
if (result == null)
field = result = computeFieldValue();
}
}
return result;
}
규칙 72 스레드 스케줄러에 의존하지 마라
- 실행할 스레드가 많을 때, 어떤 스레드를 얼마나 오랫동안 실행할지 결정하는 것은 스레드 스케줄러다. 제대로 된 운영체제라면 공평한 결정을 내리려 애쓰겠지만, 그 정책은 바뀔 수 있다. 따라서 좋은 프로그램이라면 스케줄링 정책에는 의존하지 말아야한다. 정확성을 보장하거나 성능을 높이기 위해 스레드 스케줄러에 의존하는 프로그램은 이식성이 떨어진다(non-portable).
- 안정적이고, 즉각 반응하며 이식성 좋은 프로그램을 만드는 가장 좋은 방법은, 실행 가능 스레드의 평균적 수가 프로세스 수보다 너무 많아지지 않도록 하는 것이다. 실행 가능한 스레드의 수는 모든 스레드의 수와는 다르다는 것에 주의하자. 스레드의 총 개수는 실행 가능 스레드 수보다 훨씬 많을 수도 있다. 대기 중(waiting)인 스레드는 실행 가능한 스레드가 아니다.
- 실행 가능 스레드의 수를 일정 수준으로 낮추는 기법의 핵심은 각 스레드가 필요한 일을 하고 나서 다음에 할 일을 기다리게 만드는 것이다. 스레드는 필요한 일을 하고 있지 않을 때는 실행 중이어서는 안 된다. 또한 스레드는 busy-wait해서는 안된다. 즉, 무언가 일어나길 기다리면서 공유 객체를 계속 검사해대서는 곤란하다는 것이다.
- 다른 스레드에 비해 충분한 CPU 시간을 받지 못하는 스레드가 있는 탓에 겨우겨우 동작하는 프로그램을 만나더라도, Thread.yield를 호출해서 문제를 해결하려고는 하지 마라.
- Thread.yield : 메소드를 호출한 스레드는 실행 대기 상태로 돌아가고 다른 스레드가 실행 기회를 가질 수 있도록 해준다.
- 스레드 우선순위는 자바 플랫폼에서 가장 이식성이 낮은 부분 가운데 하나다. 몇 개 스레드의 우선순위를 조정해서 프로그램의 반응 속도를 향상시키는 것은 완전히 바보짓이라 할 순 없으나, 그렇게까지 해야 할 필요가 없을 뿐더러 이식성도 없다.
프로그램의 정확성을 스레드 스케줄러 의존하지 말아라. 그런 프로그램은 안정적이지 않으며 이식성이 보장되지 않는다. 마찬가지로, Thread.yield나 스레드 우선순위에 의존하지 마라. 이런 것들은 스케줄러 입장에서는 단순히 힌트일 뿐이다. (그리고 그 힌트는 무시될 수 있다)
규칙 73 스레드 그룹은 피하라
- ThreadGroup는 보안 문제를 피하고자 고안된 것이었으나, 그 목적을 달성하진 못했다.
- 역설적이게도 ThreadGroup API의 스레드 안정성은 취약하다.
- 스레드 그룹은 이제 폐기된 추상화 단위다.
- 스레드를 논리적인 그룹으로 나누는 클래스를 만들어야 한다면, 스레드 풀 실행자(thread pool executor)를 이용하는 것이 바람직할 것이다.