스파크 완벽 가이드 - 스파크 간단히 살펴보기
by Gunju Ko
이 글은 “스파크 완벽 가이드” 책 내용을 정리한 글입니다.
저작권에 문제가 있는 경우 “gunjuko92@gmail.com”으로 연락주시면 감사하겠습니다.
스파크 완벽 가이드 - 스파크 간단히 살펴보기
1. 스파크의 기본 아키텍쳐
- 클러스터 : 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있게 만든다.
- 스파크 : 클러스터의 데이터 처리 작업을 관리하고 조율
- 스파크가 연산에 사용할 클러스터는 YARN과 같은 클러스터 매니저에서 관리한다. 사용자는 클러스터 매니저에 스파크 애플리케이션을 제출(submit)한다. 그러면 클러스터 매니저가 애플리케이션 실행에 필요한 자원을 할당한다.
1.1 스파크 애플리케이션
-
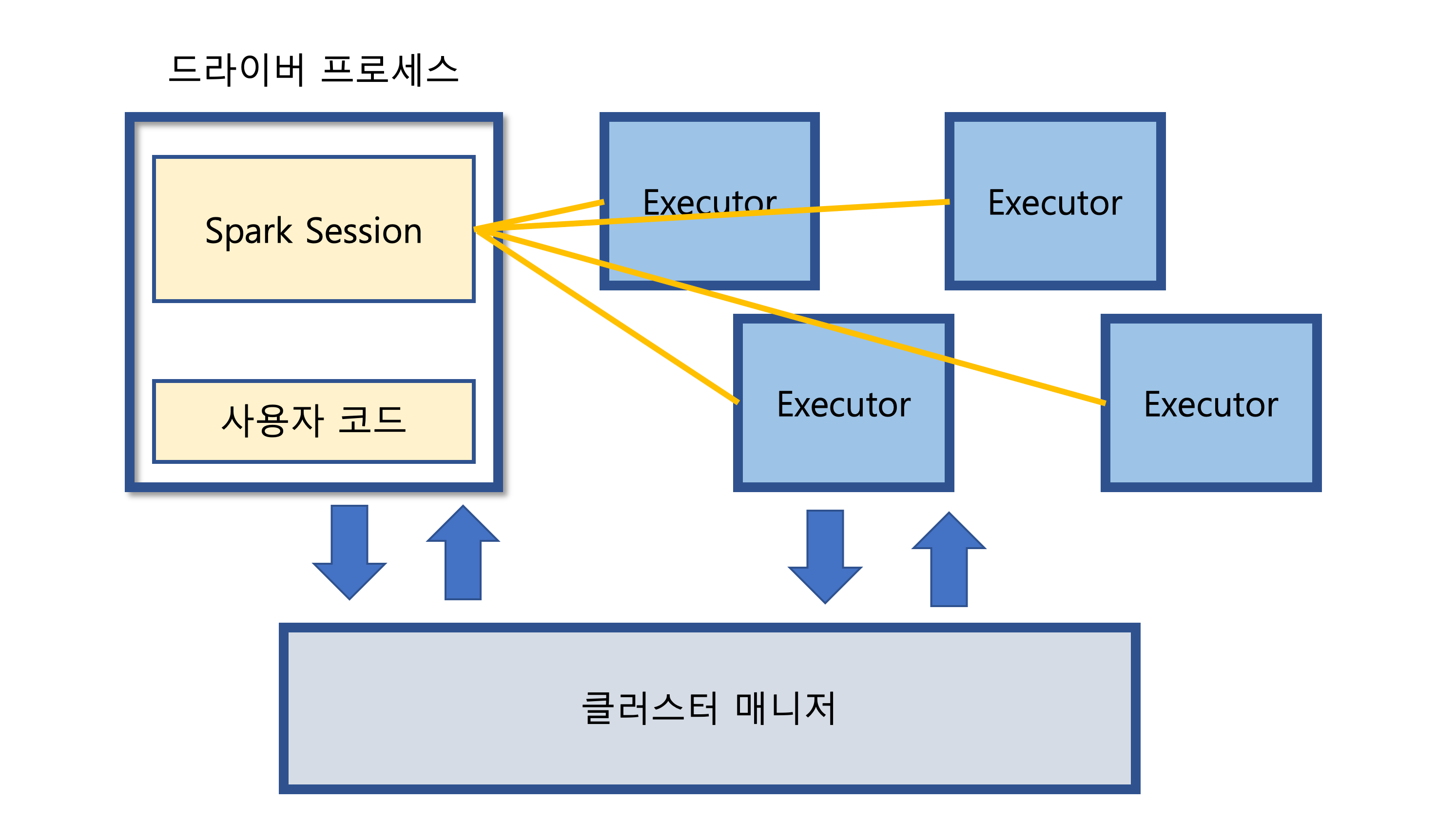
스파크 애플리케이션은 드라이버 프로세스와 다수의 익스큐터 프로세스로 구성된다.
-
드라이버 프로세스 : 클러스터 노드 중 하나에서 실행되며 main() 함수를 실행한다. 이는 스파크 애플리케이션 정보의 유지 관리, 사용자 프로그램이나 입력에 대한 응답, 전반적인 익스큐터 프로세스의 작업과 관련된 분석, 배포 그리고 스케줄링 역할을 수행하기 때문에 필수적이다.
-
익스큐터 : 드라이버 프로세스가 할당한 작업을 수행 + 진행 사항을 드라이버 노드에 보고
-
익스큐터와 드라이버는 단순한 프로스세이므로 같은 머신이나 서로 다른 머신에서 실행할 수 있음
- 스파크는 로컬 모드도 지원함. 로컬 모드로 실행하며 드라이버와 익스큐터를 단일 머신에서 스레드 형태로 실행함.
- 스파크는 사용 가능한 자원을 파악하기 위해 클러스터 매니저를 사용한다.
- 드라이버 프로세스는 주어진 작업을 완료하기 위해 드라이버 프로그램 명령을 익스큐터에서 실행할 책임이 있다.
2. 스파크의 다양한 언어 API
- 스칼라 : 스칼라가 스파크의 기본 언어임
- 자바
- 파이썬
- SQL : ANSI SQL 2003 표준 중 일부를 지원함.
- R
- 스파크는 파이썬이나 R로 작성한 코드를 익스큐터의 JVM에서 실행할 수 있는 코드로 변환함
3. 스파크 API
- 스파크가 기본적으로 두 가지 API를 제공함. 저수준의 비구조적 API + 고수준의 구조적 API
4. 스파크 시작하기
- 대화형 모드인 경우 SparkSession이 자동으로 생성된다.
- 애플리케이션의 경우 코드에서 SparkSession 객체를 직접 생성해야 한다.
5. Spark Session
- 스파크 애플리케이션은 SparkSession 이라 불리는 드라이버 프로세스로 제어한다.
- SparkSession 인스턴스는 사용자가 정의한 처리 명령을 클러스터에서 실행한다.
- 하나의 SparkSession은 하나의 스파크 애플리케이션에 대응한다.
6. DataFrame
- 가장 대표적인 구조적 API
- 테이블의 데이터를 로우와 컬럼으로 단순하게 표현
- 컬럼과 컬럼의 타입을 정의한 목록을 스키마라고 부름
- 수천대의 컴퓨터에 분산됨
스파크는 Dataset, DataFrame, SQL 테이블, RDD라는 핵심 추상화 개념을 가지고 있다. 이 개념 모두 분산 데이터 모음을 표현한다.
6.1. 파티션
- 스파크는 모든 익스큐터가 병렬로 작업을 수행할 수 있도록 파티션이라 불리는 청크 단위로 데이터를 분할한다.
- 파티션은 클러스터의 물리적 머신에 존재하는 로우의 집합이다.
- DataFrame의 파티션은 실행 중에 데이터가 컴퓨터 클러스터에서 물리적으로 분산되는 방식을 나타낸다.
- 파티션이 하나라면 수천개의 익스큐터가 있더라도 병렬성은 1이 된다. 또한 수백개의 파티션이 있더라도 익스큐터가 하나밖에 없다면 병렬성은 1이 된다.
7. 트랜스포메이션
- 스파크의 핵심 데이터 구조는 불변성(immutable)을 가진다.
- 데이터 구조를 변경하려면 트랜스포메이션을 사용해야 한다.
- 트랜스포메이션은 액션을 호출해야만 수행된다.
- 2가지 유형이 존재
- 좁은 의존성(narrow dependency) : 각 입력 파티션이 하나의 출력 파티션에만 영향을 미친다. 모든 작업이 메모리에서 일어난다.
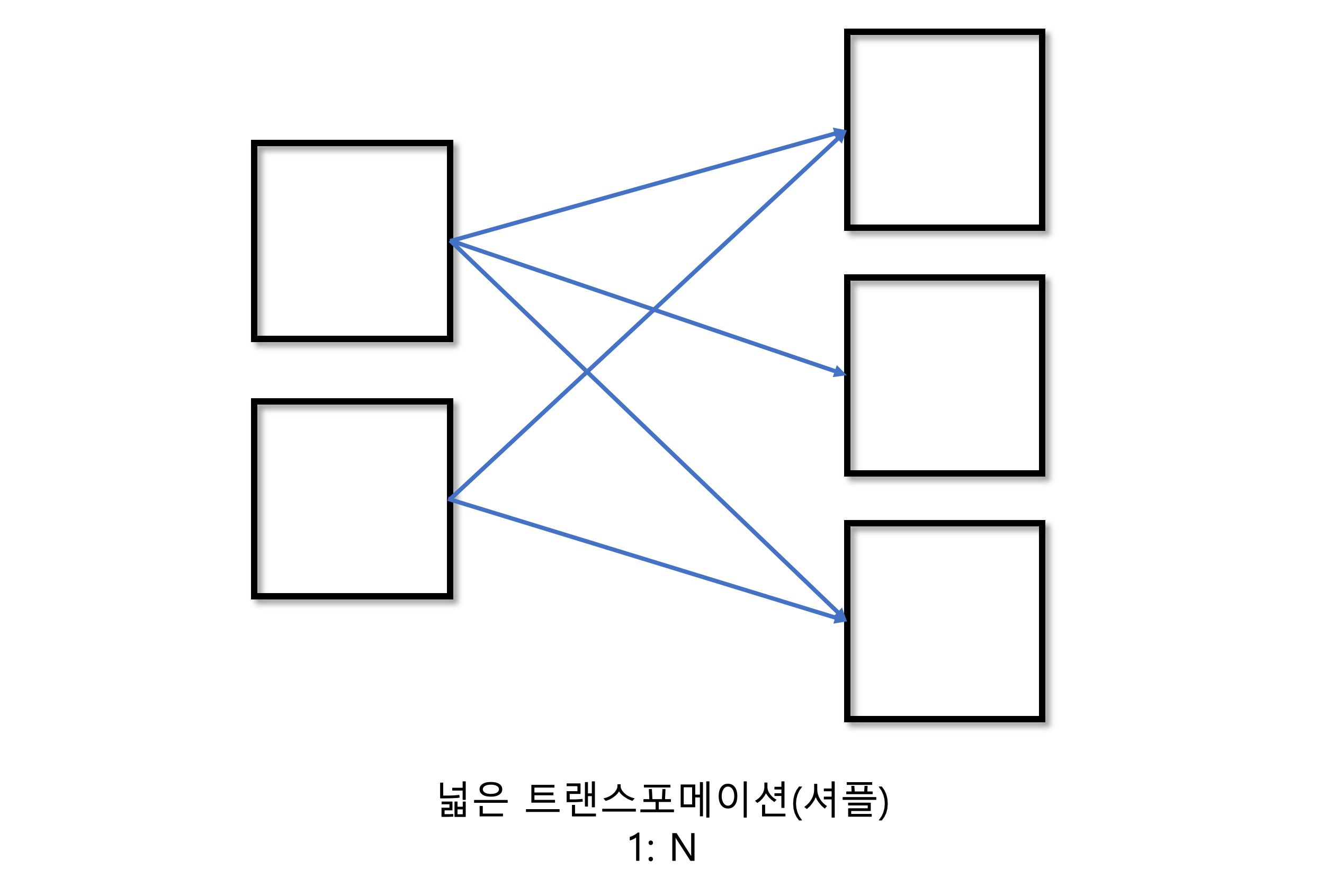
- 넓은 의존성 (wide dependency) : 하나의 입력 파티션이 여러 출력 파티션에 영향을 미친다.
- 셔플 : 스파크가 클러스터에서 파티션을 교환하는 작업. 스파크는 셔플의 결과를 디스크에 저장
- 스파크는 셔플 수행시 기본적으로 200개의 셔플 파티션을 생성 (spark.sql.shuffle.partition 설정으로 조절 가능)
7.1. 지연 연산
- 연산 그래프를 처리하기 직전까지 기다리는 동작 방식
- 연산 명령이 내려진 즉시 데이터를 수정하지 않고 원시 데이터에 적용할 트랜스포메이션의 실행 계획을 생성한다. 스파크 코드를 실행하는 마지막 순간까지 대기하다가 원형 DataFrame 트랜스포메이션을 간결한 물리적 실행 계획으로 컴파일
- 스파크는 이 과정을 거치며 전체 데이터 흐름을 최적화함 (조건절 푸시다운 등)
8. 액션
- 실제 연산을 수행하려면 액션 명령을 내려야 함
- 액션은 일련의 트랜스포메이션으로부터 결과를 계산하도록 지시하는 명령
- 세가지 유형의 액션이 있음
- 콘솔에서 데이터를 보는 액션
- 각 언어로 된 네이티브 객체에 데이터를 모으는 액션
- 출력 데이터소스에 저장하는 액션
- 액션을 지정하면 스파크 잡이 시작된다.
- 스파크 잡은 개별 액션에 의해 트리거되는 다수의 트랜스포메이션으로 이루어져 있음
9. 스파크 UI
- 스파크 UI는 스파크 잡의 진행 상황을 모니터링할 때 사용
- 스파크 잡의 상태, 환경 설정, 클러스터 상태 등의 정보를 확인할 수 있음
- 스파크 잡을 튜닝하거나 디버깅할 때 매우 유용
10. 종합 예제
- 데이터는 SparkSession의 DataFrameReader 클래스를 사용해서 읽는다. 이때 특정 파일의 포맷과 몇 가지 옵션을 함께 설정한다.
- 스키마 추론(Schema Interence) : 스파크는 스키마 정보를 얻기 위해 데이터를 조금 읽는다. 그리고 해당 로우의 데이터 타입을 스파크 데이터 타입에 맞게 분석한다.
val flightData = spark.read
.option("interSchema", "true")
.option("header", "true")
.csv("/data/filght-data/csv/2015-summary.csv")
flightData.sort("count").take(3)
- sort 메소드는 트랜스포메이션이기 때문에 호출 시 데이터에 아무런 변화도 일어나지 않는다.
- read 메소드는 액션이 호출되기 전까지 데이터를 읽지 않는다.
- DataFrame 객체에 explain 메서드를 호출하면 DataFrame의 계보(lineage)나 스파크의 쿼리 실행 계획을 확인할 수 있다.
- 실행 계획은 위에서 아래로 읽는다.
- 최종 결과는 가장 위에, 데이터 소스는 가장 아래에 있다.
- 실행 계획은 트랜스포메이션의 DAG(Directed Acyclic Graph)이며, 액션이 호출되면 결과를 만들어낸다. DAG의 각 단계는 불변성을 가진 신규 DataFrame을 생성한다.
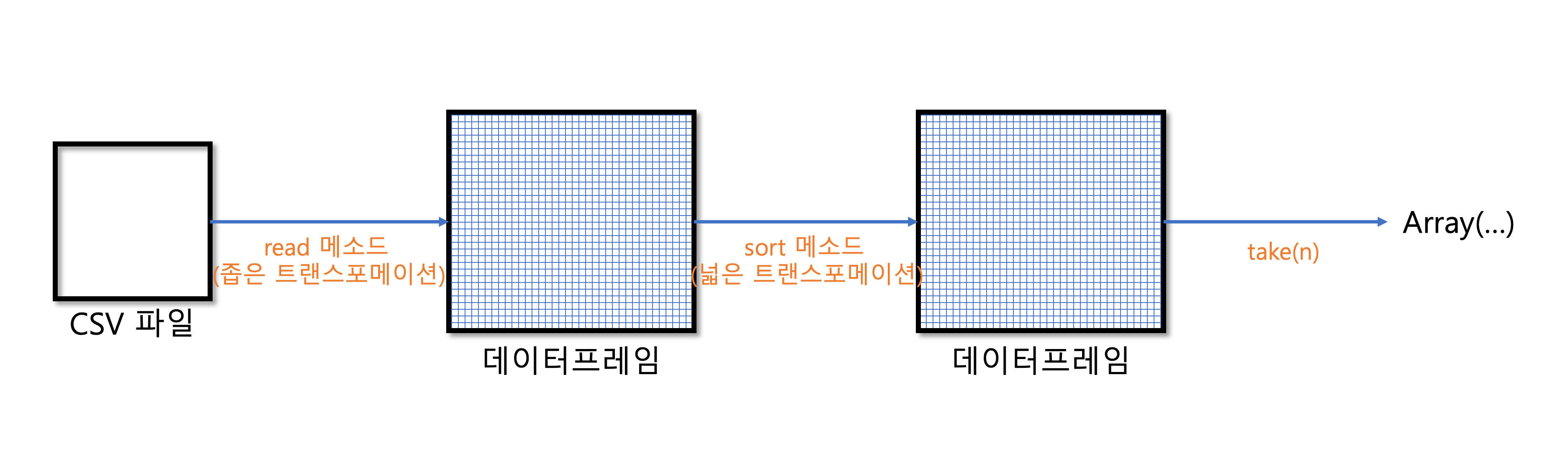
- 트랜스포메이션의 논리적 실행 계획은 DataFrame의 계보를 정의한다. 스파크는 계보를 통해 입력 데이터에 수행한 연산을 전체 파티션에서 어떻게 재연산하는지 알 수 있다.
10.1 DataFrame과 SQL
- 사용자가 SQL이나 DataFrame으로 비즈니스 로직을 표현하면 스파크에서 실제 코드를 실행하기 전에 그 로직을 기본 실행 계획으로 컴파일한다.
- 스파크 SQL을 사용하면 모든 DataFrame을 테이블이나 뷰(임시 테이블)로 등록한 후 SQL 쿼리를 사용할 수 있다.
- createOrReplateTempView 메소드를 호출하면 모든 DataFrame을 테이블이나 뷰로 만들 수 있다.
val flightData = spark.read
.option("interSchema", "true")
.option("header", "true")
.csv("/data/filght-data/csv/2015-summary.csv")
flightData.createOrReplateTempView("flight_data_2015")
val sqlWay = spark.sql("""
SELECT DESC_COUNT_NAME, count(1)
FROM flight_data_2015
GROUP BY DESC_COUNT_NAME
""")
- DataFrame에 쿼리를 수행하면 새로운 DataFrame이 반환된다.